

AIxiv 专栏是机器之心用来发布学术和技术内容的栏目。在过去的数年时间里,机器之心的 AIxiv 专栏接收并报道了超过 2000 篇的内容。这些内容覆盖了全球各大高校以及企业的顶级实验室。通过这样的方式,有效地促进了学术的交流与传播。如果您有优秀的工作想要进行分享,欢迎向我们投稿或者联系我们进行报道。投稿邮箱分别为:liyazhou@jiqizhixin.com ;zhaoyunfeng@jiqizhixin.com
在人工智能领域,“更大即更强”这一理念一直引领着大模型强化学习的发展走向。尤其是在提高大语言模型的推理能力方面,业界普遍觉得需要大量的强化学习训练数据才能够取得突破。然而,最新的研究却带来了一个让人惊喜的发现:在强化学习训练过程中,数据的学习影响力要比其数量重要得多。研究通过分析模型的学习轨迹发现,精心选择 1389 个高影响力样本,能够超越 8523 个完整样本数据集的效果。这一发现不仅对传统认知构成挑战,还揭示了一个关键事实,即提升强化学习效果的关键在于找到与模型学习历程高度匹配的训练数据。

一、挑战传统:重新思考强化学习的数据策略
近期,强化学习在提升大语言模型推理能力方面成效显著。OpenAI 的 o1 展现出强化学习在培养模型自我验证等方面的潜力;Deepseek R1 也展示了强化学习在培养模型反思等方面的潜力;Kimi1.5 同样展示了强化学习在培养模型扩展思维链等方面的潜力。这些成功案例似乎在暗示:若想获得更强的推理能力,就需要有更多的强化学习训练数据。
然而,这些开创性工作留下了一个关键问题,即到底需要多少训练数据才能够有效提升模型的推理能力呢?目前的研究中,数据量从 8000 到 150000 不等,然而却没有一个明确的答案。更重要的是,这种数据规模的不透明性带来了两个根本性的挑战。
这种情况促使研究团队提出一个本质性的问题:是否存在一种办法,能够辨别出对模型学习真正有帮助的训练数据?研究从一个基础的场景开始进行探索:直接从基座模型开始,不借助任何像 Deepseek R1-zero 那样的数据蒸馏设置。深入研究模型在强化学习过程中的学习轨迹后发现,并非所有训练数据对模型的进步贡献都相同。有些数据能显著推动模型的学习,而有些数据几乎对模型的学习没有影响。
这一发现使得研究团队研发出了学习影响力度量(Learning Impact Measurement, LIM)的方法。利用对模型学习曲线的分析,LIM 能够自动把那些与模型学习进程高度契合的样本识别出来,这些样本被称为“黄金样本”。实验结果证实了这一方法是有效的:
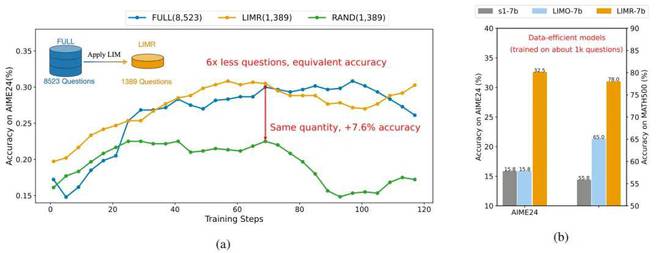
精选 1389 个样本便能够达成全量数据的效果,并且在小模型上强化学习比监督微调更具优势。
这些发现让学术界对强化学习的扩展有了新的认识:提升模型性能的关键并非仅仅是增加数据量,而是要找到那些能够切实促进模型学习的高质量样本。并且,这项研究给出了一种自动化的方式去识别这些样本,从而使高效的强化学习训练成为可能。
二、寻找 "黄金" 样本:数据的学习影响力测量(LIM)
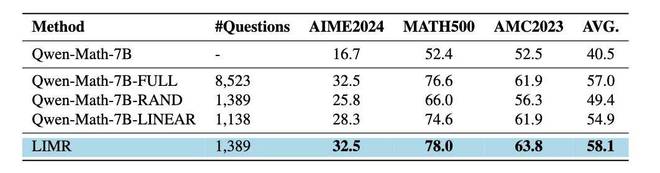
研究团队为找到真正有价值的训练样本,深入剖析了模型在强化学习过程中的学习动态。他们对包含 8,523 个不同难度级别的数学问题的 MATH-FULL 数据集进行了分析,研究者由此发现了一个有趣现象:不同的训练样本对模型学习的贡献有着显著的差别。
学习轨迹的差异性
研究者仔细观察模型训练过程中的表现时,发现了以下三种典型的学习模式:
这一发现引发了一个重要思考:能否找到最匹配模型整体学习轨迹的样本?如果能找到,是否就能实现更高效的训练?
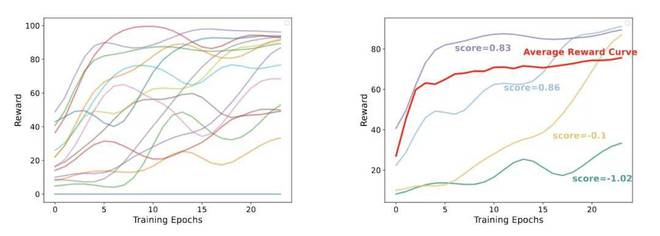
不同训练样本在训练期间所展现出来的学习模式是多样化的。样本的学习轨迹与平均奖励曲线(红色)进行了比较。
LIM:一种自动化的样本评估方法
基于上述观察,研究团队研发出了学习影响力测量(Learning Impact Measurement, LIM)这一方法。LIM 的核心理念在于:优良的训练样本应当与模型的整体学习进程保持一致。具体而言:
1. 计算参考曲线
首先,计算模型在所有样本上的平均奖励曲线作为参考:

这条曲线反映了模型的整体学习轨迹。
2. 评估样本对齐度
接着,为每个样本计算一个归一化的对齐分数:
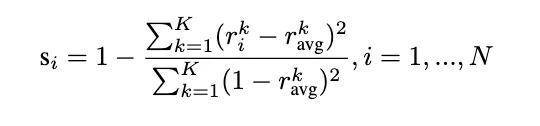
这个分数能够衡量样本的学习模式和整体学习轨迹的匹配情况。分数若较高,就意味着该样本更“有价值”。
3. 筛选高价值样本
首先设定一个质量阈值为 θ,接着选取那些对齐分数超过该阈值的样本。在实验过程中,将 θ 设置为 0.6,通过这样的方式筛选出了 1389 个高价值样本,这些样本构成了优化后的 LIMR 数据集。
对比与验证
2. 设计了第二个基线方法。
从原始数据集中随机地挑选出 1,389 个样本。
线性进度分析主要专注于那些呈现出稳定改进状态的样本。它聚焦于那些在进展方面显示出稳定提升迹象的样本。这种分析特别针对那些展现出稳定改进特点的样本。它的关注点在于那些在进度上显示出稳定提升的样本。
这些对照实验有助于我们明白 LIM 的优势。它一方面能够捕获那些呈现稳定进步的样本,另一方面也能够识别出那些在早期快速提升之后趋于稳定的具有价值的样本。
奖励设计
研究团队在设计奖励机制时,借鉴了 Deepseek R1 的经验,并且采用了简单且有效的规则型奖励函数。
这种三级分明的奖励机制能够准确地反映出模型的解题能力,同时也能够引导模型对答案的规范性予以关注。
三、实验验证:少即是多的力量
实验设置与基准
研究团队在 Qwen2.5-Math-7B 基座模型上运用 PPO 算法进行了强化学习训练,同时在多个数学基准上展开了评估,这些数学基准包含 MATH500、AIME2024 和 AMC2023 等竞赛级数据集。
主要发现
实验结果是令人振奋的。当使用 LIMR 精选的 1,389 个样本时,模型达到了用全量 8,523 个样本训练所具有的性能。并且,在某些指标上,模型还取得了比这更好的表现。
相比而言,基线模型(RAND)随机选择了相同数量的样本,但其表现明显较差,这就证实了 LIM 选择策略是有效的。
LIMR 的性能特点是用更少的数据就能取得更好的效果,将其与其他数据选择策略进行对比可知这一特点。
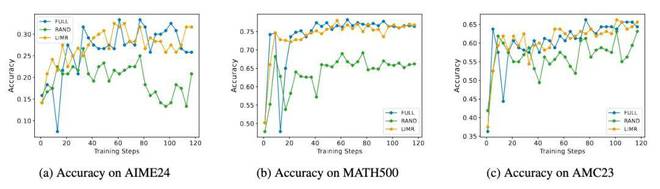
LIMR 在三个数学基准测试上的训练动态表现与全量数据是相当的,并且它显著地比随机采样更优。
训练动态分析
模型在训练过程中表现出的动态特征更有趣。LIMR 不仅在准确率方面表现出色,而且其训练过程还展现出了更稳定的特征。
这些结果验证了 LIM 方法是有效的。同时也表明,只要精心选择训练样本,就能够实现“少即是多”的效果。
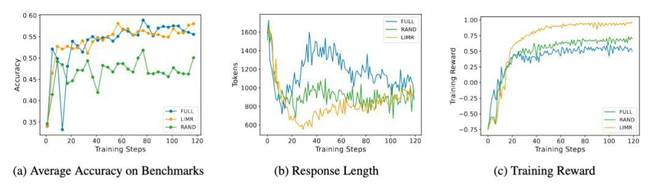
LIMR 的训练动态分析:从精选样本中获得更稳定的学习效果
四、数据稀缺场景下的新发现:RL 优于 SFT
研究者们在探索高效训练策略时发现了一个现象。这个现象令人深思。在数据稀缺且模型规模较小的场景下,强化学习的效果比监督微调的效果显著要优。
研究者们为了验证这一发现,设计了一个对比实验。这个实验精心设计,使用相同规模的数据,其中有来自 s1 的 1000 条数据,还有来自 LIMO 的 817 条数据。分别通过监督微调和强化学习来训练 Qwen-2.5-Math-7B 模型。结果令人印象深刻。
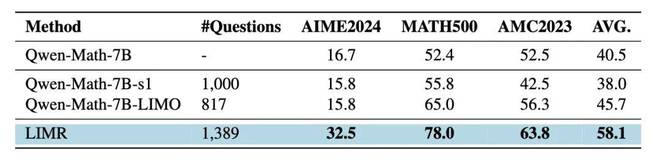
小模型上的策略对比:强化学习的 LIMR 优于监督微调方法
这一发现意义重大。LIMO 和 s1 等方法已证明在 32B 规模模型上通过监督微调能实现高效推理能力。然而,研究显示,对于 7B 这样的小型模型,强化学习或许是更优的选择。
这个结果揭示了一个重要的点:在资源有限的场景当中,选择恰当的训练策略比一味地追求更具难度的数据更加关键。研究者们把强化学习和智能的数据选择策略进行结合,从而找到了提升小型模型性能的一条有效路径。
参考资料:
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://www.mjgaz.cn/fenxiang/274367.html
