
Anthropic 憋了大半年,终于释放出了重要的举动——首款混合推理模型 Claude 3.7 Sonnet 隆重地出现在人们面前!
Claude 系列中,这是到目前为止最为智能的一个模型。它几乎能够做到及时响应,还能够进行可扩展且逐步的思考。

简言之,一个模型,两种思考方式。
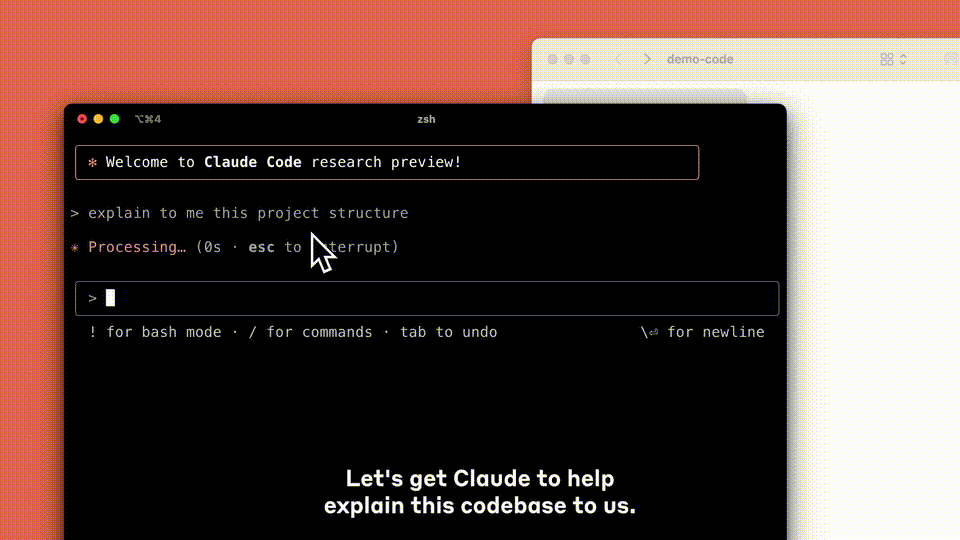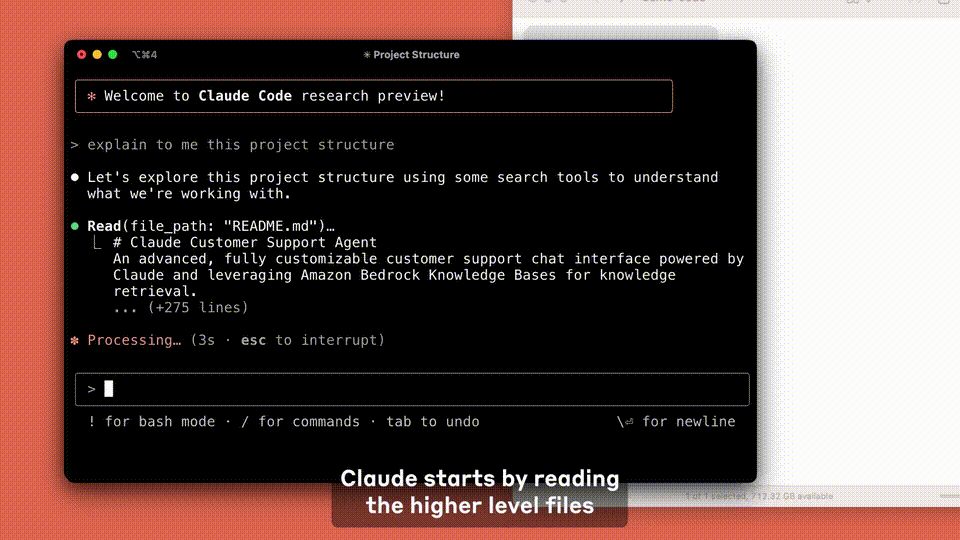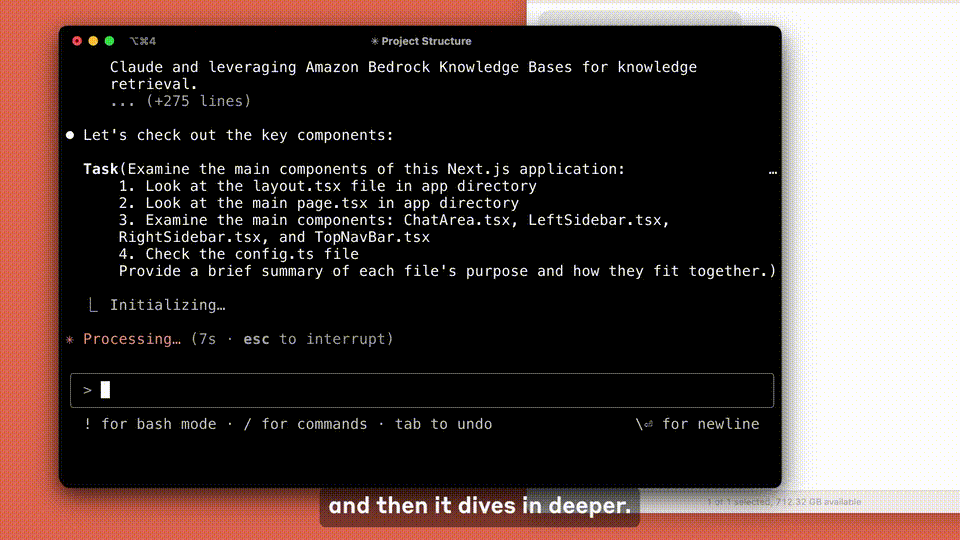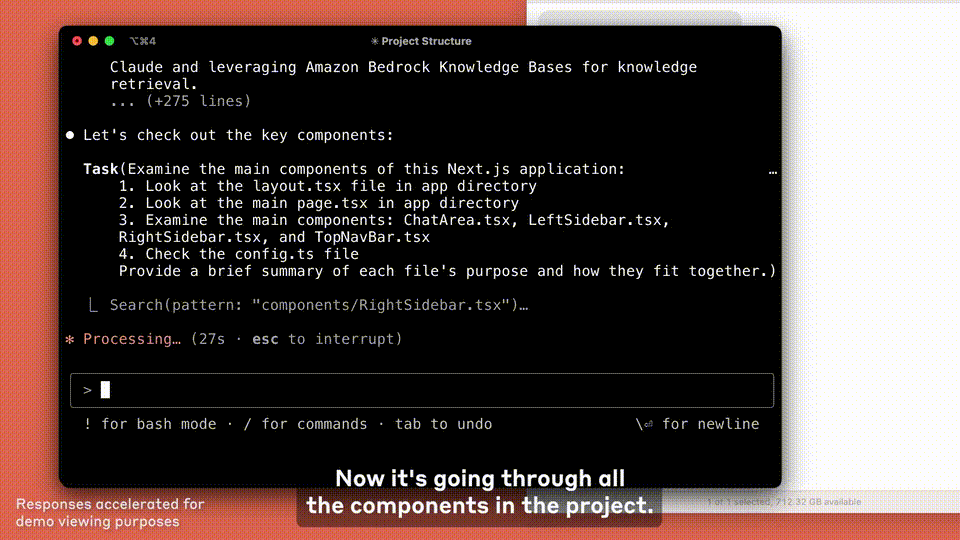
假设你想要破解一个博弈论数学方面的问题,也就是蒙提霍尔问题。你将这个问题扔给 Claude 3.7 Sonnet ,接着同时选择了“Extended”模式。
它便会展示详细CoT过程,用时52秒就完成了。
关键在于,Claude 3.7 Sonnet 当前对所有人都是免费可用的,并且目前“扩展思考”模式尚未上线。
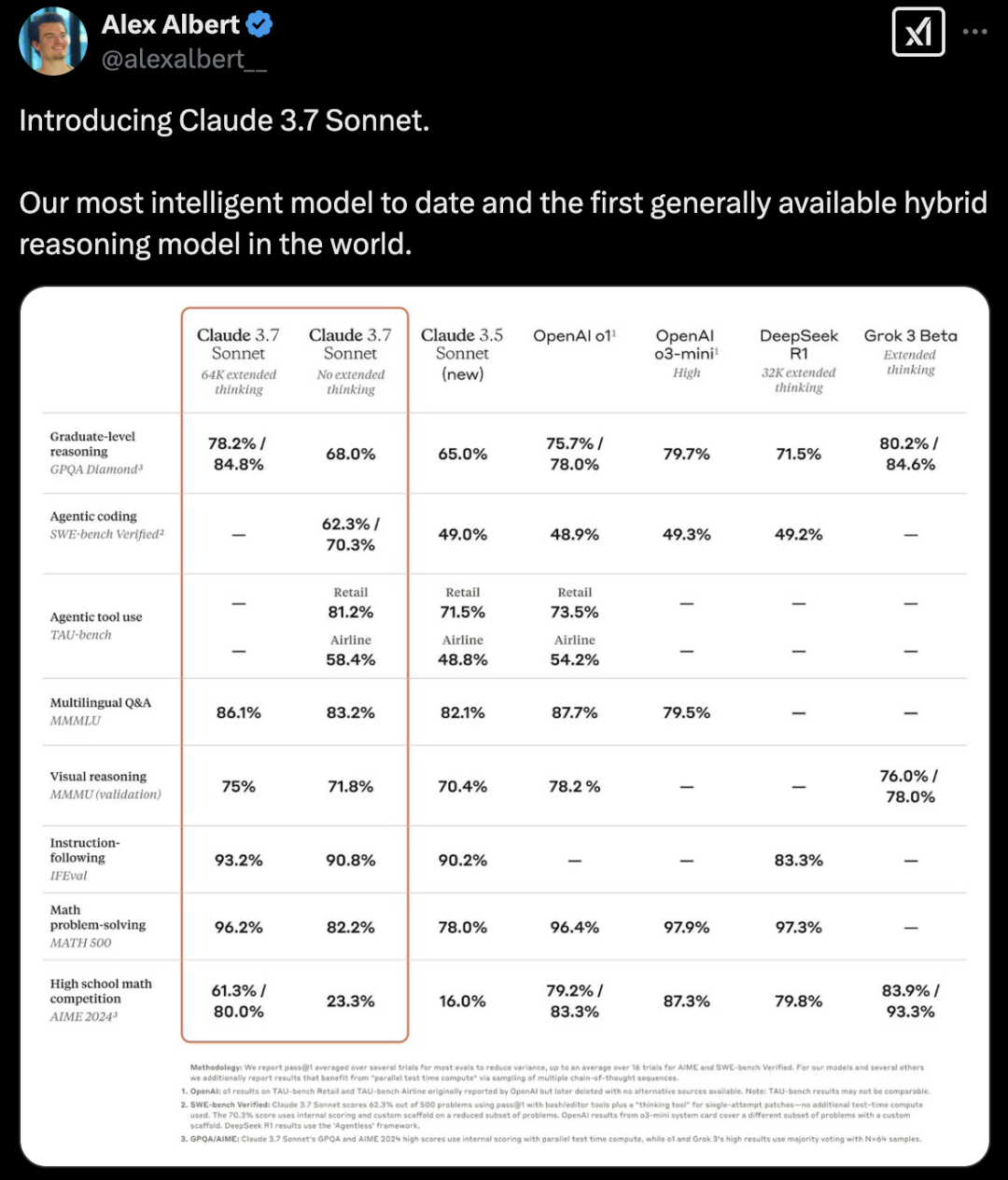
在多项基准测试里,Claude 3.7 Sonnet 在“扩展思考”模式的加持下,在数学方面刷新了 SOTA,在物理方面刷新了 SOTA,在指令执行方面刷新了 SOTA,在编程方面刷新了 SOTA。
相较于上一代 Claude 3.5 Sonnet,数学方面的能力暴涨 10%以上,编码能力也暴涨 10%以上。
Claude 3.7 Sonnet(64k extended thinking)在除数学之外的领域几乎全面超越了 o3-mini 和 DeepSeek R1,并且与 Grok 3 的表现处于相近水平。
API用户可以精确控制模型的思考时间
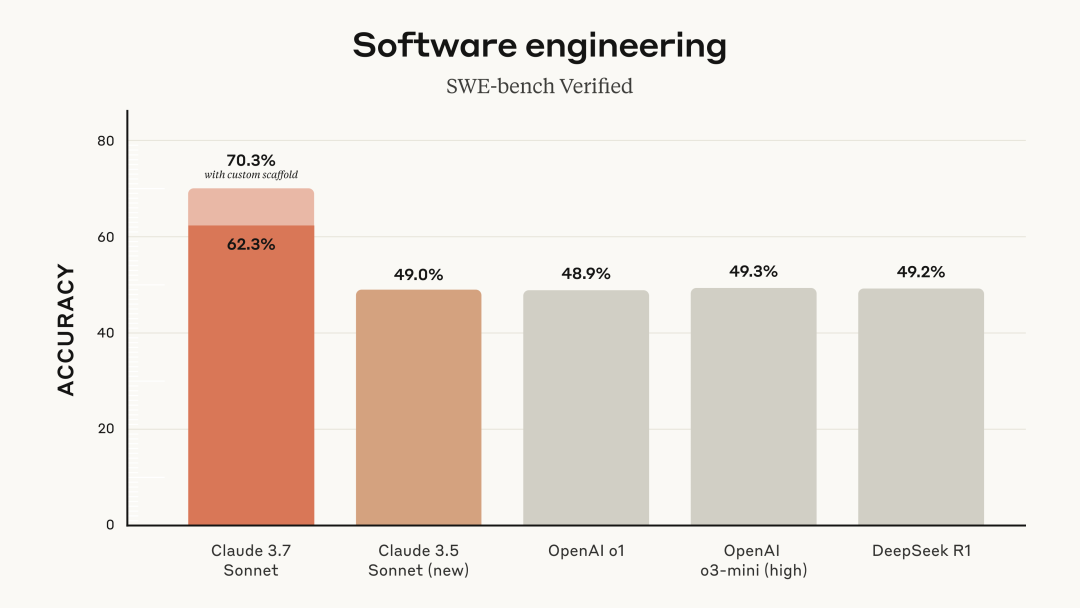
可以说,Claude 3.7 Sonnet 完全是一个最为强大的“软件工程 AI”。它在 SWE-bench 上取得了 70.3%的高分。
与此同时,今天问世了首款“智能体编程”工具 Claude Code(预览版)。
如今,它在 Anthropic 内部已成为不可或缺的工具。在早期测试阶段,Claude 仅用一次就能够完成原本需要人类花费 45 分钟才能完成的任务。
也就是说,你做产品经理,AI给你打工写代码。
没有 Claude 4 以及 Anthropic 所采取的这种突然的行动,这确实给 AI 界带来了又一次的震撼。
这半个月,注定是2025开年以来AI含金量最高的。
Grok 3 在上周发布了。这周,DeepSeek 连续开源了 5 天。据说 OpenAI 的 GPT-4.5 也要上线。另外,还有 Claude 3.7 Sonnet。大模型领域的混战再次开始了。

全球首款「混合推理」模型诞生
Anthropic 在官方博文中称,Claude 3.7 Sonnet 是他们迄今为止最为智能的模型。同时,它也是市场上首个混合推理模型。
Claude 3.7 Sonnet 能够产生即时响应,也能够逐步展示思考过程的详细步骤,且这些步骤对用户是可见的。API 用户还可以对模型的思考时间进行精细控制。
Claude 3.7 Sonnet 在编码方面有显著提升。Claude 3.7 Sonnet 在前端网页开发方面有显著提升。
他们推出了一款命令行工具,名为 Claude Code。这款工具是用于智能体编码的。
目前,Claude Code 是以有限的研究预览版的形式提供的。它具备这样的功能,即能让开发人员从他们的终端出发,把大量的工程任务委托给 Claude。
推理,是一个LLM整体能力
Claude 3.7 Sonnet 的设计理念与市场上其他推理模型的设计理念有所不同。
Anthropic 认为,人类通过一个大脑来分别处理快速反应以及深度思考,同理,推理应当是前沿模型所具备的整体能力,并非是一个完全孤立的模型。这种将推理视为整体能力的方式为用户带来了更流畅的使用体验。
Claude 3.7 Sonnet 在部分方面显示出了这一理念。
Claude 3.7 Sonnet 首先是普通的语言模型(LLM),其次它还是一个推理模型。它能够让使用者选择在某些时候希望模型正常回答,而在另一些时候希望它在回答之前思考更长的时间。
Claude 3.7 Sonnet 在标准模式下。它是 Claude 3.5 Sonnet 的升级版本。
它在扩展思考模式下会进行自我反思,然后再回答问题。这样做提高了它在数学方面的性能,提高了它在物理方面的性能,提高了它在指令遵循方面的性能,提高了它在编码方面的性能,也提高了它在其他许多任务上的性能。
通常,两种模式对模型的提示效果相似。
其次,用户在通过 API 使用 Claude 3.7 Sonnet 时,还能够对思考的预算进行控制。
你可以告知 Claude 在回答时思考的 tokens 数量有上限,这个上限为 128K tokens 的输出限制。这样用户就能在速度(以及成本)与回答质量之间做出权衡了。
第三,在开发推理模型的过程中,Anthropic 对于数学和计算机科学竞赛问题的优化程度有所降低。同时,它将重点转移到了更能体现企业实际使用 LLM 的现实世界任务上。
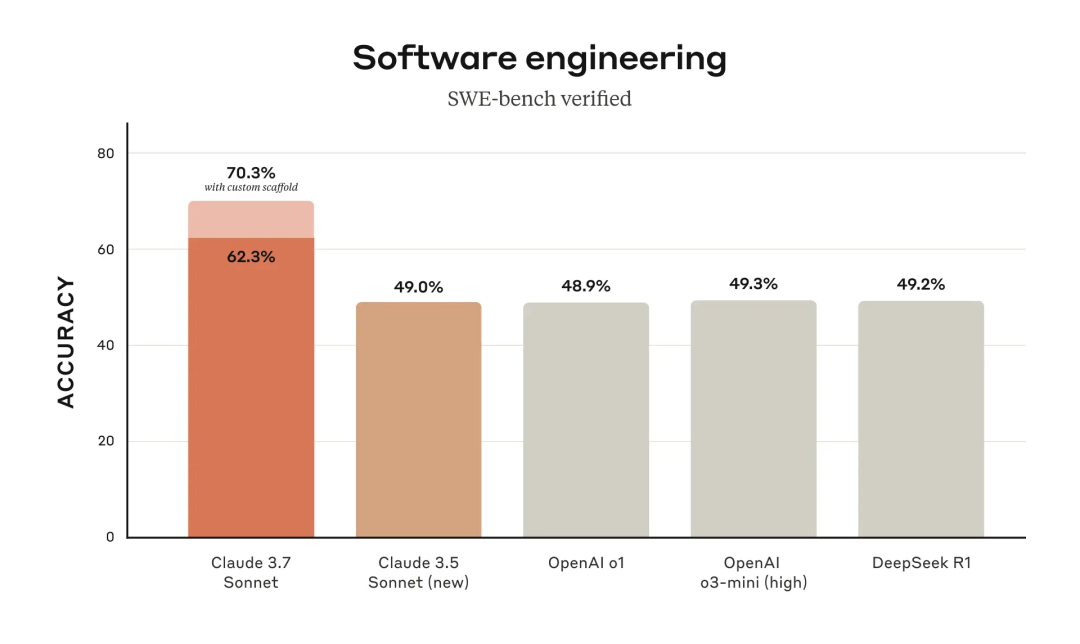
Claude 3.7 Sonnet 在 SWE-bench Verified 上达到了 SOTA 水平。这个评测的目的是对 AI 模型解决现实世界软件问题的能力进行评估。
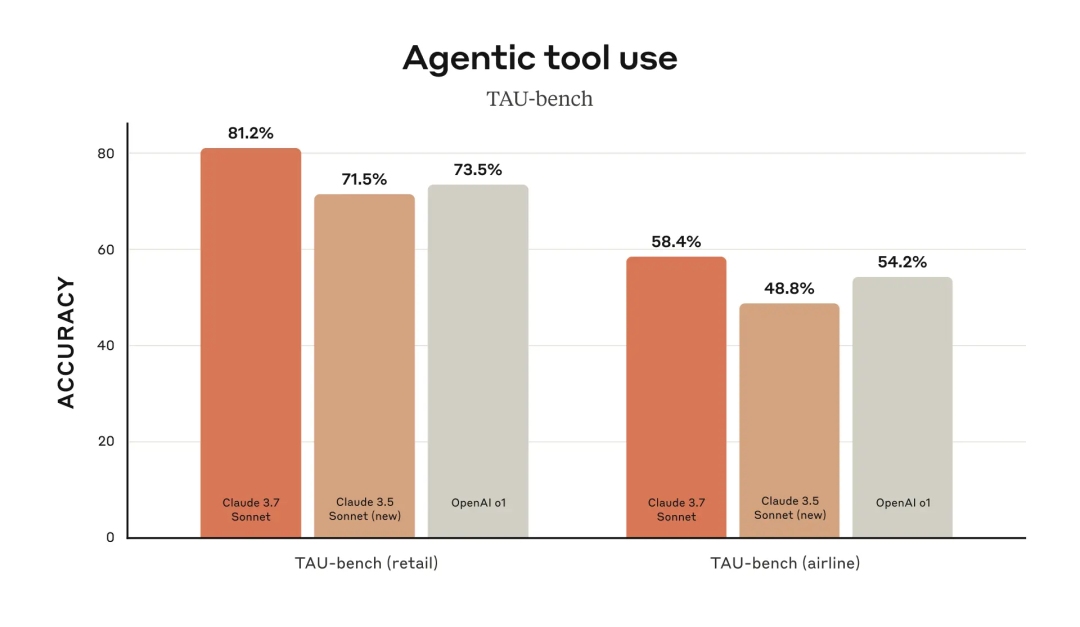
Claude 3.7 Sonnet 在 TAU-bench 这个框架上刷新了 SOT。TAU-bench 是用于测试 AI 智能体在复杂现实世界任务中与用户和工具交互能力的。
如前所说,Claude 3.7 Sonnet 在众多的基准测试里,其性能有了明显的提升。
Claude 3.7 Sonnet(64k extended thinking)与最新的 Grok 3 Beta 模型相比,在推理方面几乎不分上下。在数学和视觉推理方面,它比 Grok 3 Beta 稍差一些。
与 DeepSeek R1 相比,带有扩展思考模式的 Claude 3.7 Sonnet 在除数学之外的方面拿下最高分。
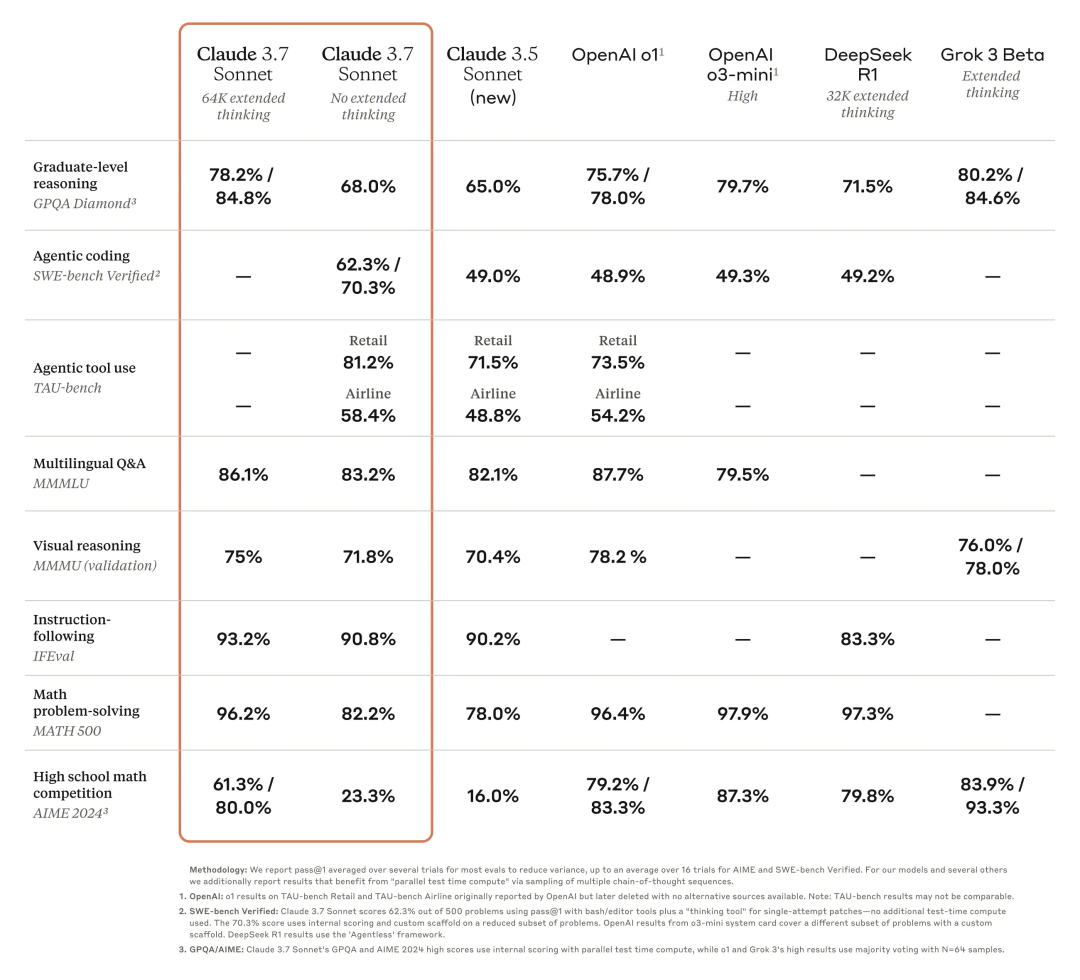
Claude 3.7 Sonnet 在任务指令的跟随方面表现出色,在通用推理方面表现出色,在多模态能力方面表现出色,在自主编程方面表现出色。扩展思考模式给数学领域带来了显著提升,给科学领域带来了显著提升。除了传统的基准测试之外,它在宝可梦游戏测试中甚至超越了所有先前的模型。
AI编码智能体,一次完成45分钟任务
2024 年 6 月之后,Sonnet 系列一直被全球开发者视为首选模型。
今天,Anthropic 诞生了首个智能体编码工具 Claude Code,目前是以限量研究预览的形式进行发布。
Claude Code 会主动去协作。它能够进行搜索和阅读代码的操作,也能够编辑文件。同时,它还可以编写和运行测试,能够提交代码并将其推送至 GitHub。此外,它还会使用命令行工具,并且在每一步操作中都能确保用户参与其中。
此外,本次更新还改进了Claude.ai上的编码体验。
现在,Claude 的所有套餐都具备支持 GitHub 集成的功能。开发者可以把代码仓库直接与 Claude 进行连接。
Anthropic 迄今最强大的编码模型是 Claude 3.7 Sonnet,它能更深入地理解个人项目、工作项目和开源项目,还能一举成为修复 bug 的强大助手,能开发新功能,也能编写 GitHub 文档。
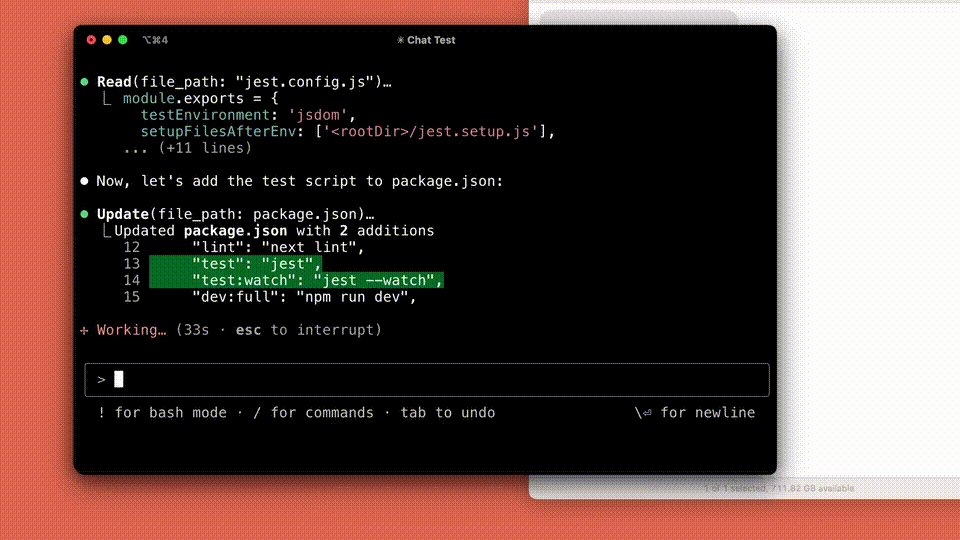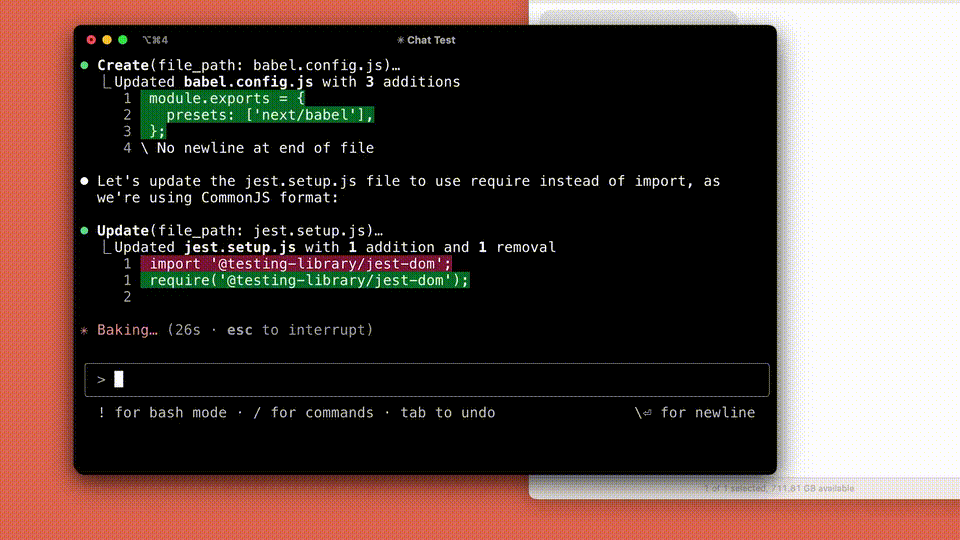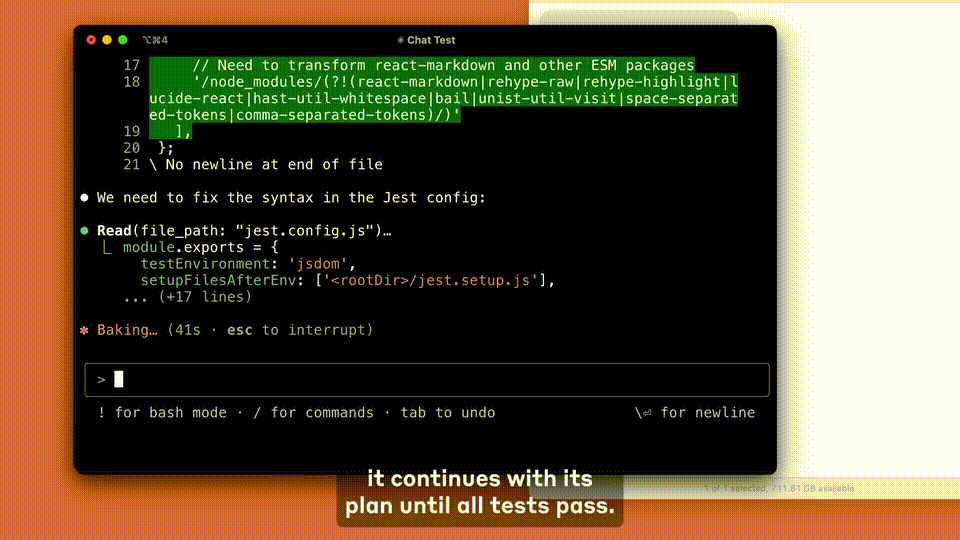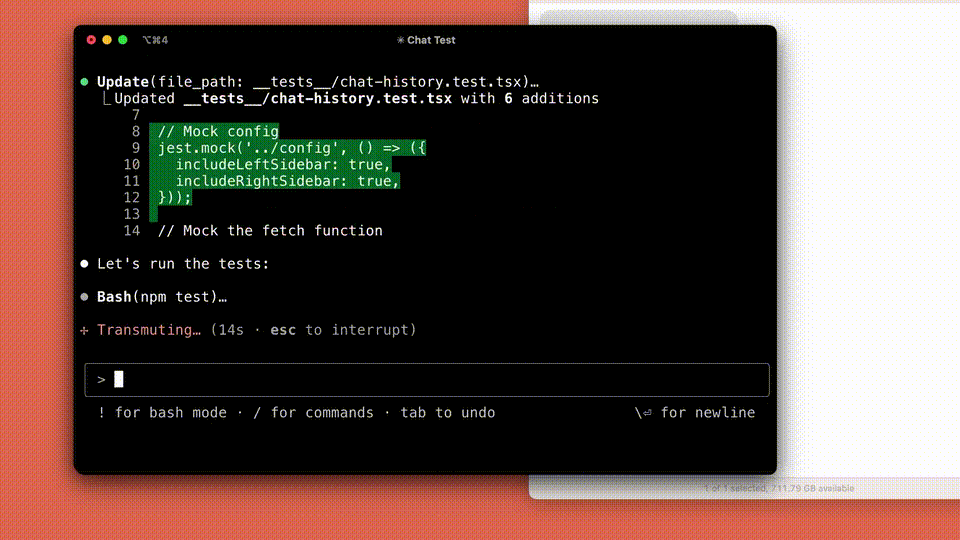
目前,Claude Code尚处于早期阶段。然而,它已经成为Anthropic团队不可或缺的工具。尤其在测试驱动开发方面,它发挥着重要作用。在调试复杂问题时,它也是不可或缺的。在大规模重构方面,同样有着重要的地位。
在早期测试中,它能够一次性完成通常需要手动工作的任务,且这个任务原本需要 45 分钟以上。这显著减少了开发时间和工作量。
在接下来的几周内,Anthropic 打算依据使用情况持续进行改进。其一,提升工具调用的可靠性;其二,增加对长时间运行命令的支持;其三,改进应用内渲染效果;其四,扩展 Claude 对自身能力的理解。
全新的测试时Scaling

Claude作为AI智能体
Claude 3.7 Sonnet 拥有一项新特性,名为「行为扩展」(action scaling)。这种改进让它能够迭代调用函数,能够响应环境的变化,还能够持续操作直到完成开放式任务。
在计算机使用方面:Claude 可以通过发出虚拟鼠标点击和键盘按键来替代用户执行任务。与之前的版本相比,Claude 3.7 Sonnet 在计算机使用任务中能够投入更多的交互次数,并且配备了更充足的时间和计算资源,所以往往能够获得更好的结果。
这一进步在 OSWorld 评估中得以体现,OSWorld 是用于评估多模态 AI 智能体能力的测试平台。
Claude 3.7 Sonnet 在一开始就有不错的表现。随着它持续和虚拟计算机进行交互,它的性能优势会随着时间的流逝而持续扩大。
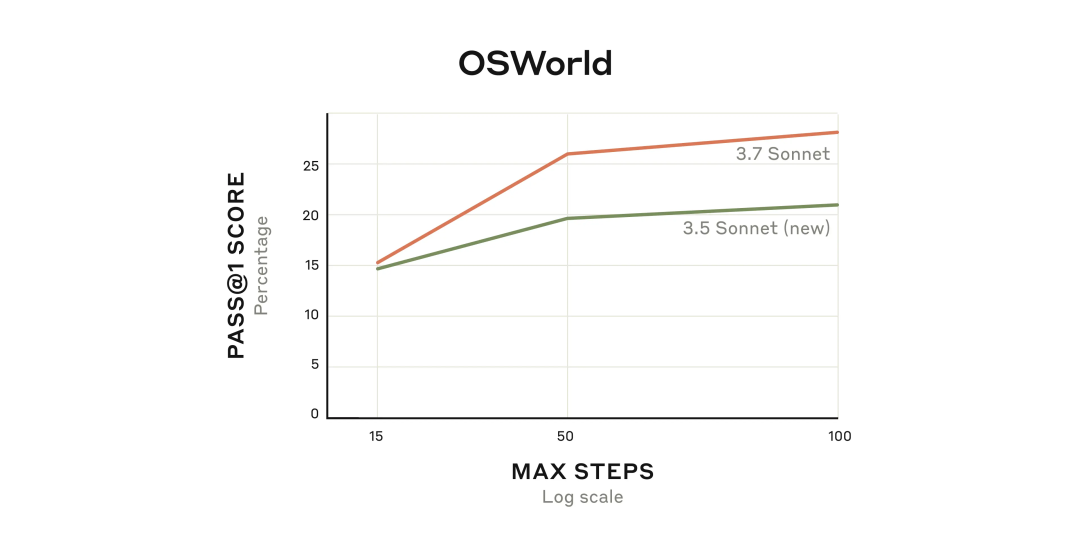
Claude 的扩展思考模式与 AI 智能体训练相互结合,一方面帮助它在 OSWorld 等众多标准评估里取得了更优的表现,另一方面也让它在一些其他未曾预料到的任务中实现了重大的突破。
以玩游戏作为例子,尤其是在 Game Boy 掌机的经典游戏「口袋妖怪:红」中的表现。他们给 Claude 赋予了基础记忆的能力,还有屏幕像素的输入功能,以及按键操作和屏幕导航的函数调用能力。这样它就能够突破常规的上下文限制,持续进行游戏,能够实现长达数万次的持续交互。
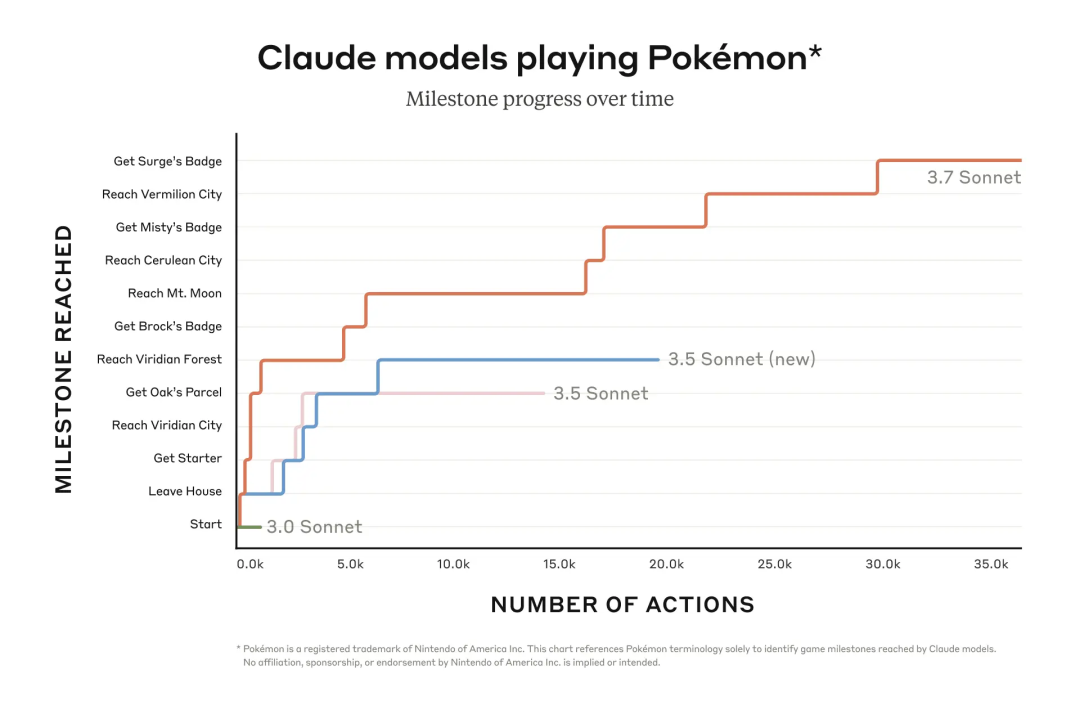
在下图里,他们将具备扩展思考能力的 Claude 3.7 Sonnet 与之前版本的 Claude Sonnet 在口袋妖怪游戏中的进度进行了对比。
如图所示,早期版本在游戏刚开始的时候就很难向前推进。Claude 3.0 Sonnet 连走出故事起点真新镇的初始小屋都做不到。
Claude 3.7 Sonnet 通过改进后的 AI 智能体能力取得了明显的进步,它成功地对三位道馆馆主发起了挑战并且将他们击败,进而获得了相应的徽章。
Claude 3.7 Sonnet 在尝试诸多策略方面表现很出色,并且它还会重新审视已有的假设,这些使得它在游戏过程中能够不断提升自身的能力。
串行与并行测试时计算Scaling
Claude 3.7 Sonnet 在运用其扩展思考能力时,可以被认为它利用了某种机制。这种机制是在进行串行测试时进行计算的。
它会在生成最终输出之前,执行多个推理步骤,且这些步骤是连续的。同时,在这个过程中,它会持续增加计算资源的投入。
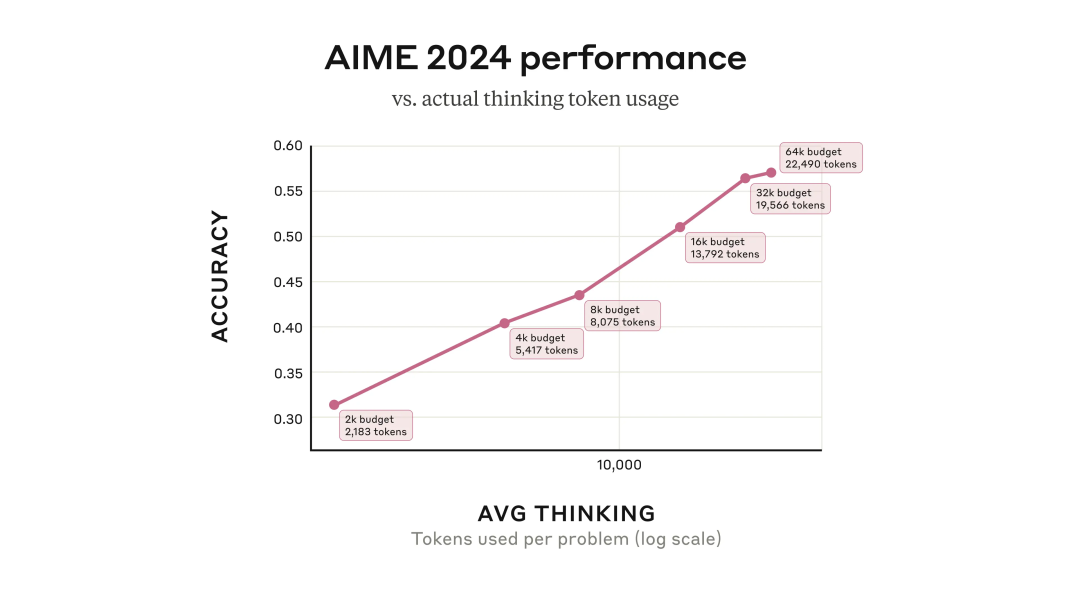
这种机制总体来看能够提升性能表现,且方式是可预测的。比如在数学问题求解时,其准确率会随着允许采样的“思考 Token”数量增加而呈对数增长。
Claude 的研究人员正在探索一种方式,那就是在使用并行测试的时候运用计算,以此来提升模型的性能。
具体方法是对多个独立的思维过程进行采样,并且在不知道正确答案的情况下挑选出最佳结果。这种挑选可以通过多数表决或者共识投票机制来达成,也就是选择出现次数最多的答案当作“最佳”答案。
也可以使用另一个 LLM 去验证其工作成果,或者运用经过训练的评分函数来挑选出最优答案。
这些优化策略以及相关的研究工作已经在多个 AI 模型的评估报告里被验证了。 这些优化策略在多个 AI 模型的评估报告中得到了验证。 相关的研究工作在多个 AI 模型的评估报告中也得到了验证。 这些优化策略的相关研究工作已在多个 AI 模型的评估报告中得以验证。 多个 AI 模型的评估报告验证了这些优化策略及相关研究工作。 多个 AI 模型的评估报告对这些优化策略及相关研究工作进行了验证。 这些优化策略及相关研究工作在多个 AI 模型的评估报告中均得到了验证。 这些优化策略和相关研究工作在多个 AI 模型的评估报告中获得了验证。 多个 AI 模型的评估报告证实了这些优化策略及相关研究工作。 这些优化策略及相关研究工作在多个 AI 模型的评估报告里都得到了验证。 多个 AI 模型的评估报告验证了这些优化策略以及相关研究工作。 这些优化策略及相关研究工作在多个 AI 模型的评估报告中被证实了。 这些优化策略及相关研究工作在多个 AI 模型的评估报告中得到了证实。 多个 AI 模型的评估报告对这些优化策略及相关研究工作予以了验证。 这些优化策略及相关研究工作在多个 AI 模型的评估报告中获得了证实。 这些优化策略及相关研究工作在多个 AI 模型的评估报告里被确认了。 多个 AI 模型的评估报告确认了这些优化策略及相关研究工作。 这些优化策略及相关研究工作在多个 AI 模型的评估报告中得到了确认。 多个 AI 模型的评估报告对这些优化策略及相关研究工作进行了确认。 这些优化策略及相关研究工作在多个 AI 模型的评估报告中被予以了验证。 这些优化策略及相关研究工作在多个 AI 模型的评估报告中被予以了确认。 这些优化策略及相关研究工作在多个 AI 模型的评估报告中被给予了验证。 这些优化策略及相关研究工作在多个 AI 模型的评估报告中被给予了确认。 这些优化策略及相关研究工作在多个 AI 模型的评估报告中得到了认可。 多个 AI 模型的评估报告认可了这些优化策略及相关研究工作。 这些优化策略及相关研究工作在多个 AI 模型的评估报告中被认可了。 多个 AI 模型的评估报告对这些优化策略及相关研究工作予以了认可。 这些优化策略及相关研究工作在多个 AI 模型的评估报告中获得了认可。 这些优化策略及相关研究工作在多个 AI 模型的评估报告里被认可了。
在 GPQA 评估里,他们在并行测试的时候通过计算 Scaling 获得了突破性的进展。
具体而言,它调用了相当于 256 个独立样本的计算资源。同时结合了经过训练优化的评分模型。并且设置了最大 64,000 个 Token 的推理限额。在这些条件下,Claude 3.7 Sonnet 在 GPQA 测试中取得了 84.8%的总体得分,其中物理学部分的得分高达 96.5%。
值得注意的是,即便超出了常规多数表决所规定的限制范围,模型的性能依然在不断地提升。
下图列出了评分模型方法和多数表决方法的详细结果。
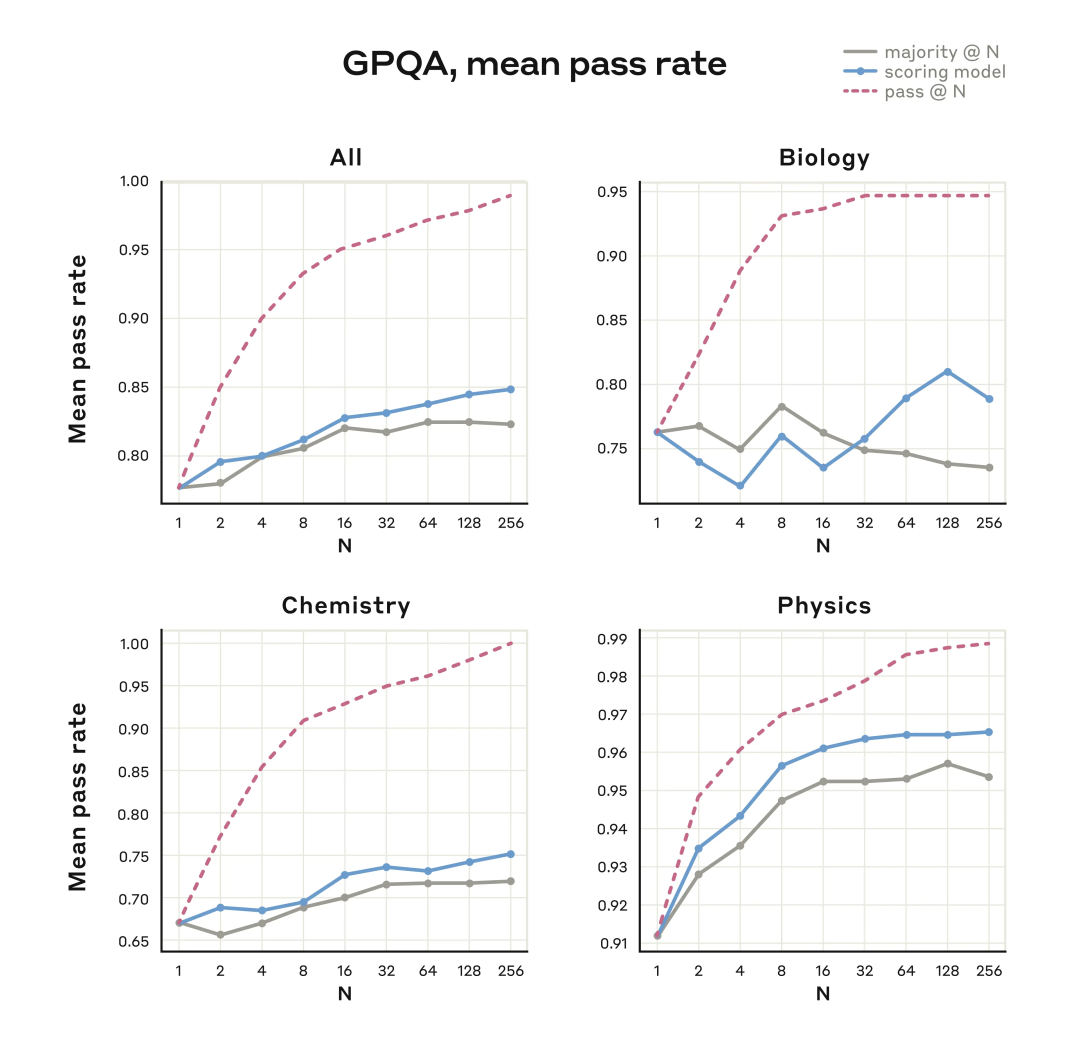
这些方法可以提升 Claude 回答的质量,并且一般不需要等待它完成推理过程。Claude 同时进行多个不同的深度思维运算,就能够探索更多的问题解决思路,从而显著提升正确答案的输出频率。
三步路线图,Claude合作者已来
Claude 3.7 Sonnet 标志着迈出了重要一步,Claude Code 也标志着迈出了重要一步,这是向真正增强人类能力的人工智能系统的迈进。
它们具有深入推理的能力,能够自主工作,还能有效协作。凭借这些能力,让我们更接近一个未来,在那个未来里,人工智能丰富了人类能够实现的事情。
如今,Claude合作者已来。

最新版,可以免费用了
值得一提的是,Claude 3.7 Sonnet 目前已在 Claude.ai 平台上线。Web 用户可以免费体验,iOS 用户可以免费体验,Android 用户也可以免费体验。
希望构建自定义 AI 解决方案的开发者,能够借助 Anthropic API 来进行访问;也可以通过 Amazon Bedrock 进行访问;还可以通过 Google Cloud 的 Vertex AI 进行访问。
Claude 3.7 Sonnet 在标准模式下价格为 3 美元/百万输入 token,在扩展思考模式下价格为 15 美元/百万输出 token,且这其中包含了思考 token 的费用,其价格与前代产品相同。
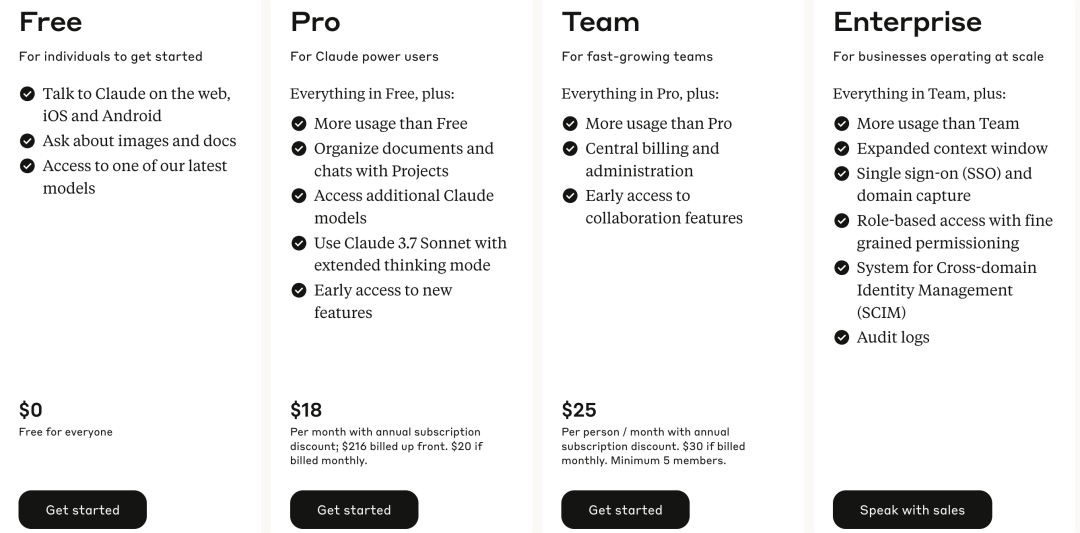
Anthropic套餐定价
AI大佬测试
宾夕法尼亚大学沃顿商学院的教授 Ethan Mollick 于过去几天对 Claude 3.7 进行了测试。
Claude 3.7 时常给他带来和初次使用 GPT-4 时一样的感受:既深感惊叹,又对它们的能力怀有一丝不安。就拿 Claude 的原生编码能力来说,如今我们能够通过自然对话或者文档获取可以运行的程序,并且不需要具备任何编程技能。
他给 Claude 提供了一份有关新型 AI 教育工具的提案,接着在对话里要求它“用 3D 形式展示所提议的系统架构且让其具有交互性”。最终,它做出了我们论文中核心设计的交互式可视化效果,且没有出现任何错误。
这些图形较为简洁,然而并非最令人印象深刻的部分。真正令人惊叹的是,Claude 自主地决定把它制作成一个逐步演示,用以解释相关概念,而这并非是我们让它去做的。
这种对需求的预判和对新方法的思考是AI领域中的一项新突破。
再举一个更有意思的例子,Ethan Mollick 对 Claude 说:“给我制作一个能交互的时间机器装置,使我能够穿越到过去,并且在过去发生一些有趣的事情。挑选一些不同寻常的时间点让我回去……”另外还有“添加更多的图像。”
仅仅有这两条提示之后,就出现了一个功能完备的交互式体验,并且还配有像素图像。这些图像虽然粗糙,但很迷人,实际上令人惊讶地印象深刻。AI 必须使用纯代码来“绘制”这些图像,它无法看到自己正在创建的内容,就如同一个被蒙住眼睛的艺术家。
参考资料:
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://www.mjgaz.cn/fenxiang/274472.html
