
昨晚,Anthropic 要发布新模型的消息在 AI 社区开始广泛传播,然而这并非是人们期待中的 Cl2227e65e54f2a355efbf92c68513c00c51013f32cf9c734578a6c945b1413d1ude 4.0,而是 3.7 Sonnet 版本。

图源:
今天凌晨,Anthropic 的新旗舰模型按时到来。它正式发布了到目前为止最为智能的模型,同时也是市面上首款混合推理模型,名为 Claude 3.7 Sonnet。
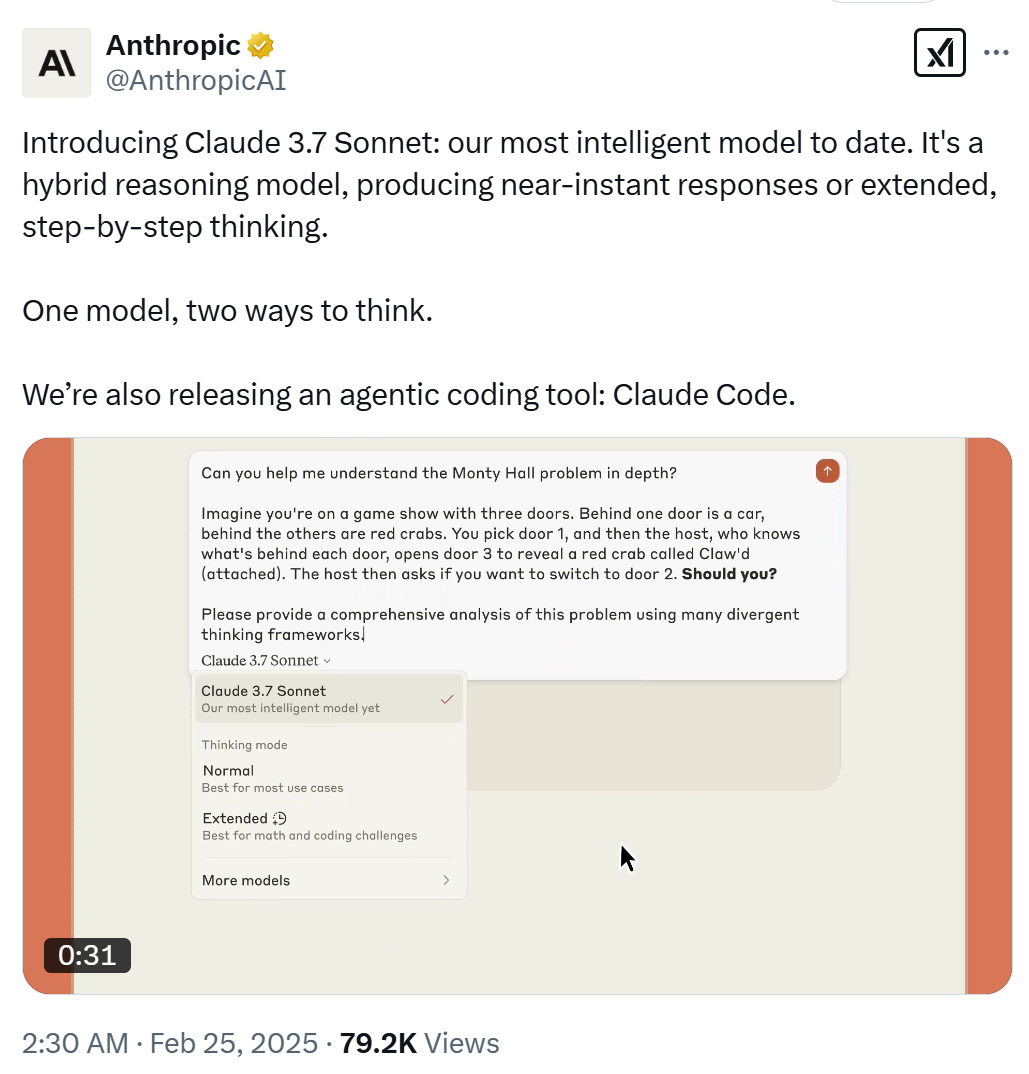
Claude 3.7 Sonnet 能够产生几乎是即时的响应,也能够向用户展示扩展的以及逐步的思考。Anthropic 称,有“一个模型,两种思考方式”,也就是标准思考模式和扩展思考模式。并且,API 用户还可以对模型的思考时间进行细致的控制。
Anthropic 在发布 Claude 3.7 Sonnet 之后,还推出了用于智能编码的命令行工具 Claude Code。此工具目前以有限的研究预览版本的形式被使用,能够让开发人员直接从他们的终端把大量工程任务委托给 Claude。
Anthropic 在编码方面对 Claude.ai 的编码体验进行了改进。其 GitHub 集成现在已在所有 Claude 计划中提供,这样一来,开发人员就能够把他们的代码存储库直接与 Claude 连接起来。Claude 会深入了解个人、工作以及开源项目。通过这样的了解,它将成为用户在 GitHub 项目中进行修复错误、开发功能以及构建文档等工作的更强大合作伙伴。
因此,Claude 3.7 Sonnet 在编码和前端 web 开发方面具有功能与改进,这使它成为 Anthropic 到目前为止最好的编码模型。
目前,新模型 Claude 3.7 Sonnet 能够通过所有的 Claude 计划来使用,这些计划包括 Free、Pro、Team 和 Enterprise,同时也可以通过 Anthropic API、Amazon Bedrock 和 Google Cloud Vertex AI 来使用。除了免费用户之外,所有其他用户均可体验扩展思考模式。
Claude 3.7 Sonnet 在标准和扩展思考模式下,其价格与 Claude 3.5 Sonnet 相同。每百万输入 token 的价格是 3 美元,每百万输出 token 的价格是 15 美元,这里的价格包含思考 token。
一位网友评价道,“Anthropic 的每次发布都能让人露出微笑,并且能让人感到兴奋!”
最强 Claude 3.7 Sonnet
让前沿推理触手可及
Anthropic 表示,它开发 Claude 3.7 Sonnet 的理念与市面上其他推理模型存在差异。人类会使用单个大脑来进行快速反应和深度思考,Anthropic 觉得推理应当体现前沿模型的综合能力,而非仅仅是完全独立的模型。这种统一的方式能够为用户带来更无缝的体验。
Claude 3.7 Sonnet 遵循上述理念,从而形成了诸多独有优势。
Claude 3.7 Sonnet 首先它既是普通的 LLM ,同时也是推理模型。你能够选择在什么时候希望模型正常进行回答,以及在什么时候希望它在回答之前进行更长时间的思考。在标准模式之下,Claude 3.7 Sonnet 是前代 Claude 3.5 Sonnet 的一种升级版。在扩展思维模式下,它会先进行自我反思,然后再回答问题,这样就能提升它在数学、物理、遵循指令、编码以及许多其他任务方面的表现。Anthropic 察觉到,在这两种模式下,模型的提示词的工作方式是相近的。
其次,使用 API 调用 Claude 3.7 Sonnet 时,用户能够控制思考预算。用户可以告知 Claude 思考的 token 数量不超过 N 个。对于任意的 N 值,其输出被限制为 128K 个 token 。这样就使得用户可以在速度(以及成本)与答案质量之间进行权衡。
第三,Anthropic 在开发自家的推理模型时,对数学和计算机科学竞赛问题的优化力度较小。它将重点转移到了更能体现企业实际使用 LLM 方式的现实任务上。
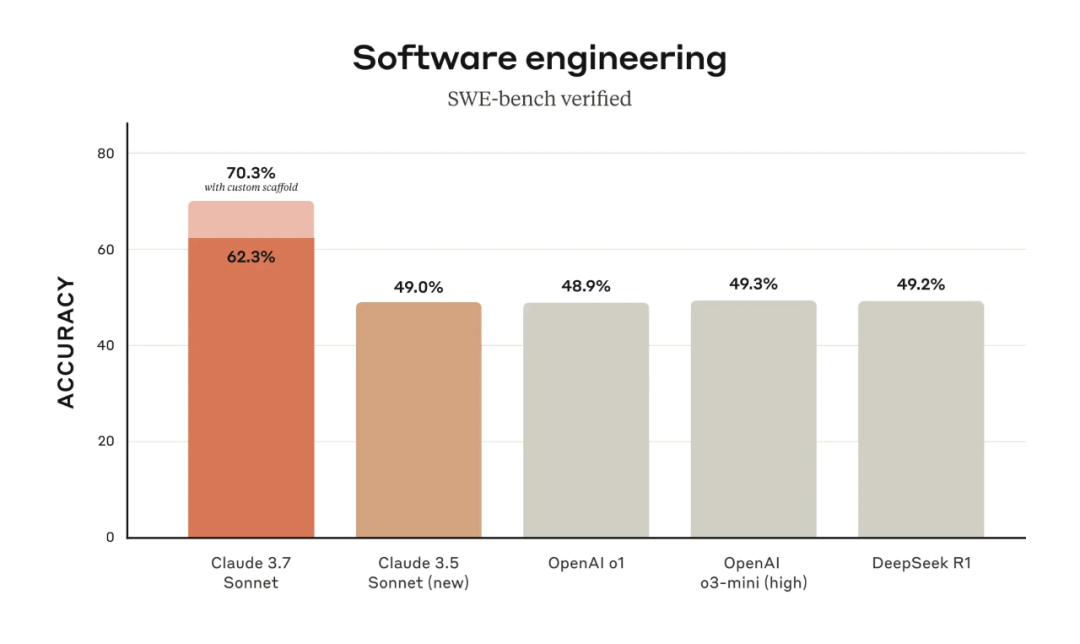
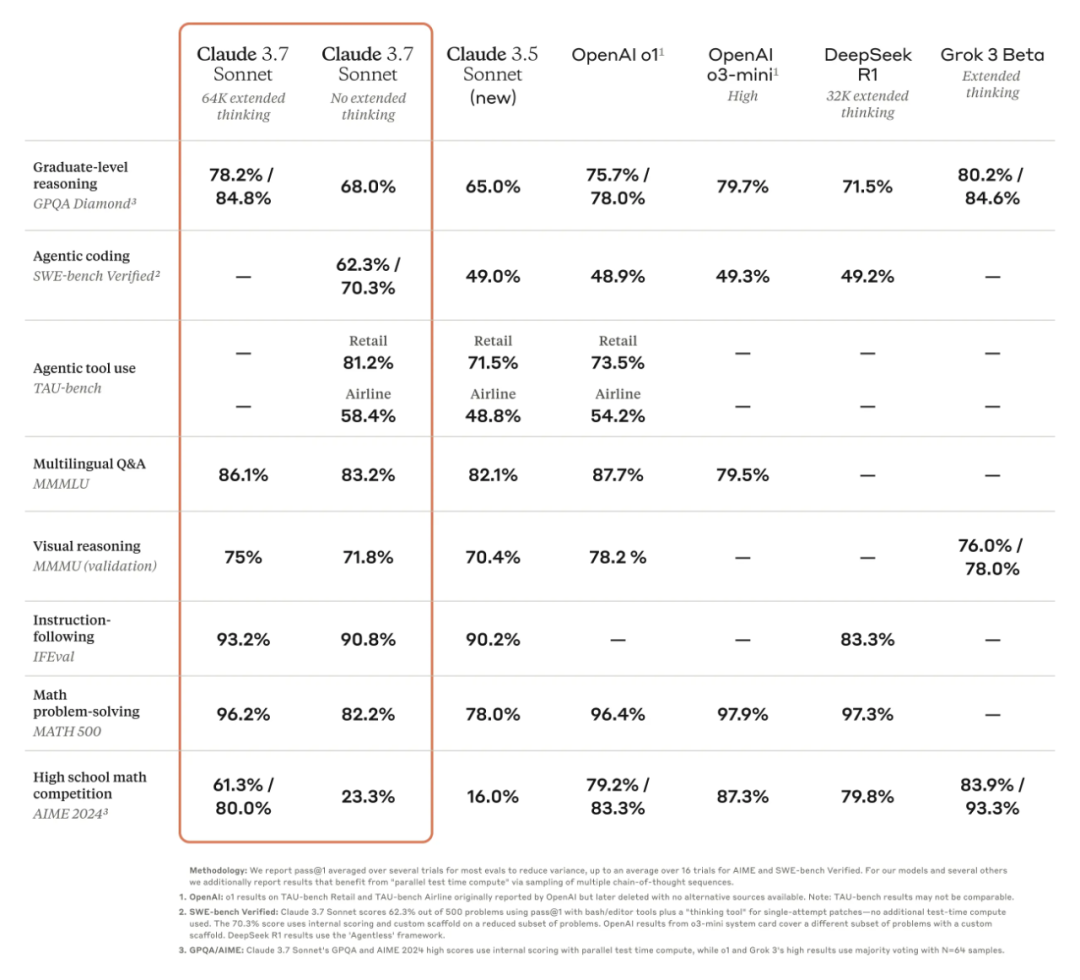
我们来看 Claude 3.7 Sonnet 的基准测试结果。在 SWE-bench Verified 这个评估 LLM 解决 GitHub 上真实软件问题能力的基准测试数据集上,Claude 3.7 Sonnet 达到了 SOTA 性能,它比 Claude 3.5 Sonnet 强很多,也比 OpenAI 的 o3-mini (high) 和 o1 以及 DeepSeek R1 都要优秀得多。
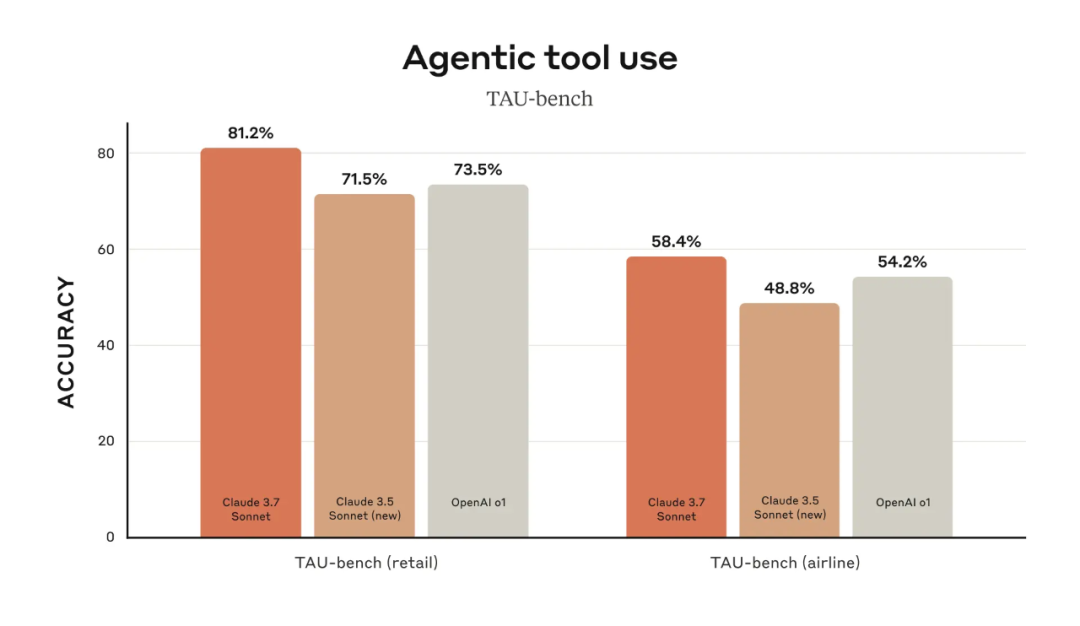
在 TAU-bench 这个评估 LLM 在复杂真实场景中用户与工具交互能力的基准测试平台上,Claude 3.7 Sonnet 达成了 SOTA 性能。它的表现超过了 Claude 3.5 Sonnet 以及 OpenAI 的 o1。
Claude 3.7 Sonnet 在指令遵循方面表现出色,在通用推理方面表现出色,在多模态能力方面表现出色,在智能编码方面表现出色。扩展思考在数学方面实现了显著提升,扩展思考在科学方面实现了显著提升。但 Claude 3.7 Sonnet 在一些方面依然不及 OpenAI 的 o3-mini (high),Claude 3.7 Sonnet 在一些方面依然不及 Grok-3 Beta。
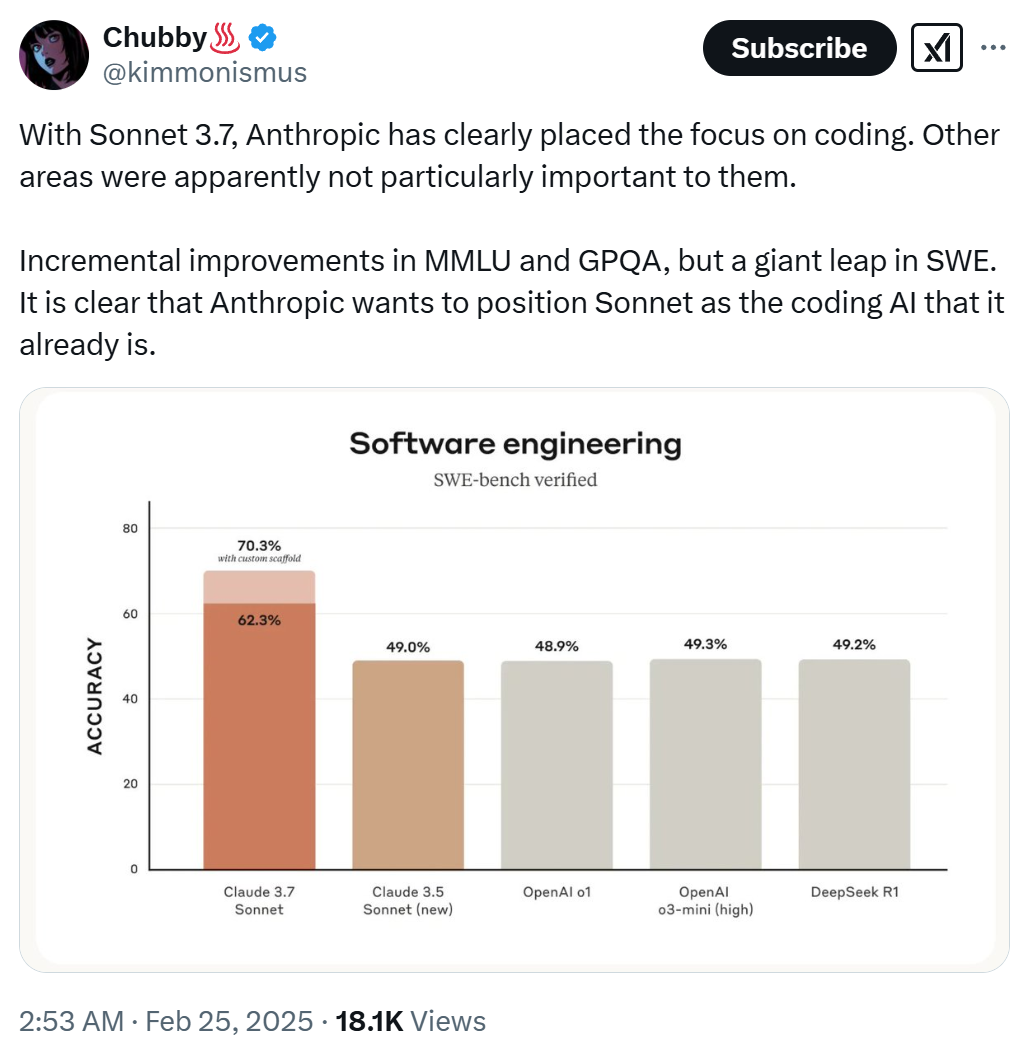
可以看到,Anthropic 对于 Claude Sonnet 3.7,重点放在了编码能力方面,而其他领域看起来并不是特别重要。很明显,Anthropic 想要把 Sonnet 定位为编码 AI,并且它实际上已经是了。
图源:
另外,Claude 3.7 Sonnet 除了传统基准之外。它在宝可梦(Pokémon)游戏测试中能够超越所有以前的模型。
Anthropic 已经开展了大量的早期测试,并且是与合作伙伴一起进行的。这些测试证明了 Claude 在编码能力方面处于全面领先的地位。
其中,Cursor 表明 Claude 再度成为现实世界编码任务的最优选择,无论是处理复杂的代码库,还是在高级工具使用方面,都有明显的改进。Cognition 发觉,Claude 在规划代码更改以及处理全栈更新方面,比任何其他模型都要优秀得多。
Vercel 强调了 Claude 在复杂代理工作流程里的精确度很高。Replit 已经成功地部署了 Claude,用于从头开始构建复杂的 Web 应用程序和仪表板,而其他模型没有进展。在 Canva 的评估中,Claude 一直能编写出具有卓越设计品味且可用于生产的代码,还大幅降低了错误。
Claude Code
智能编码让开发更便捷
2024 年 6 月之后,Sonnet 一直被全球开发者当作首选模型。今日,Anthropic 推出了它的首个智能编码工具 Claude Code,此为有限的研究预览版本,从而进一步强化了开发者的能力。
Claude Code 在功能方面是一个积极的协作者,它能够搜索代码并进行阅读,还可以编辑文件,能够编写和运行测试,也可以提交和推送代码至 GitHub,同时还能使用命令行工具。
我们来看下它的几个使用示例,比如解释项目结构:
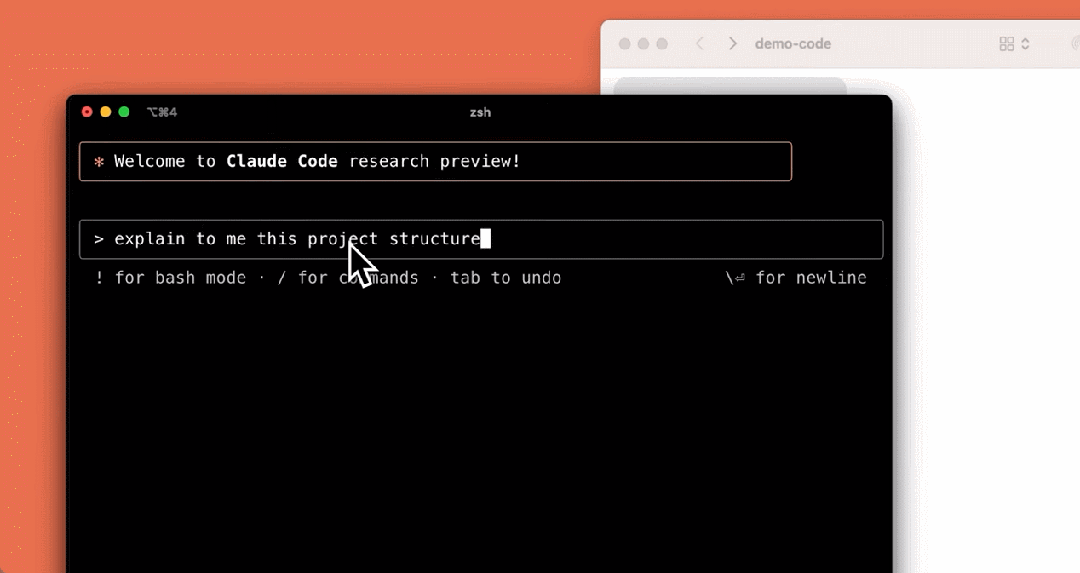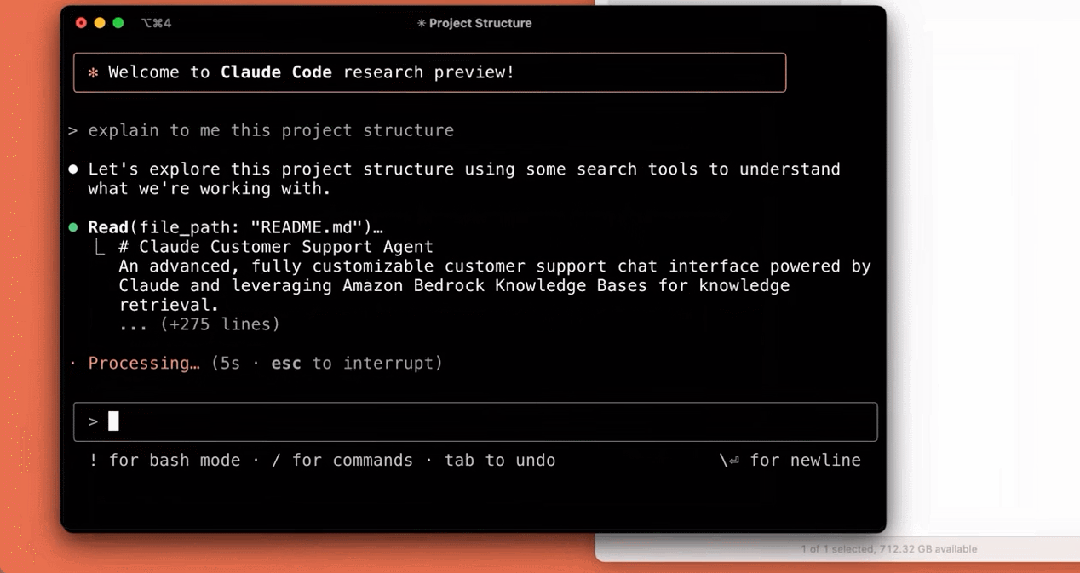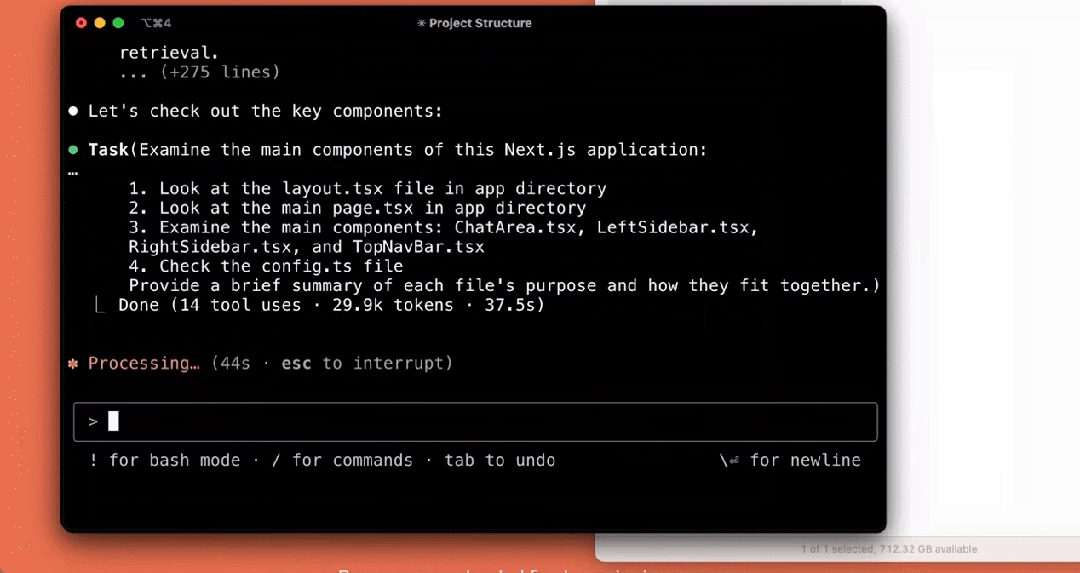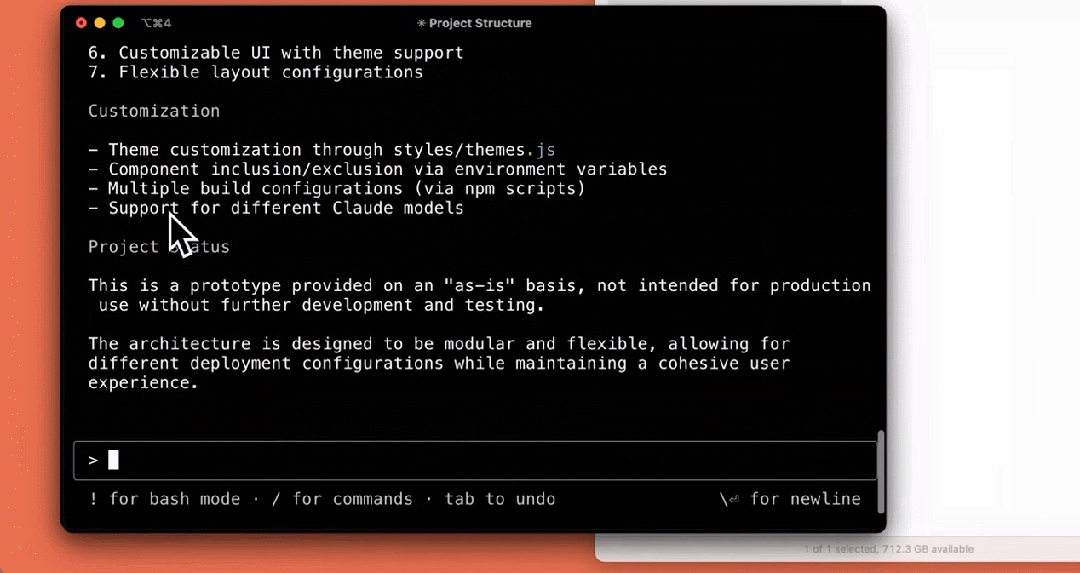
编写测试:
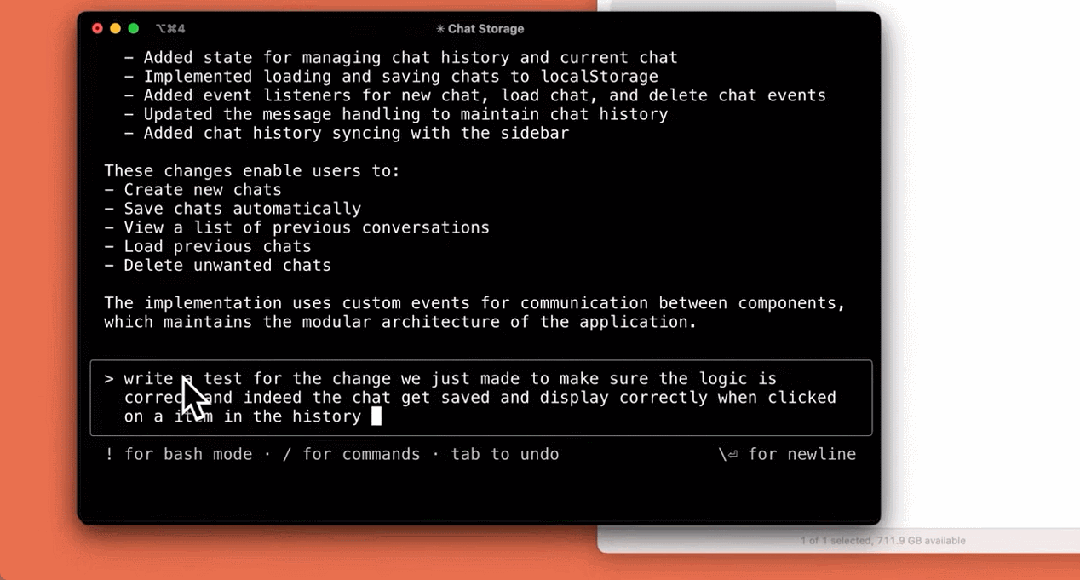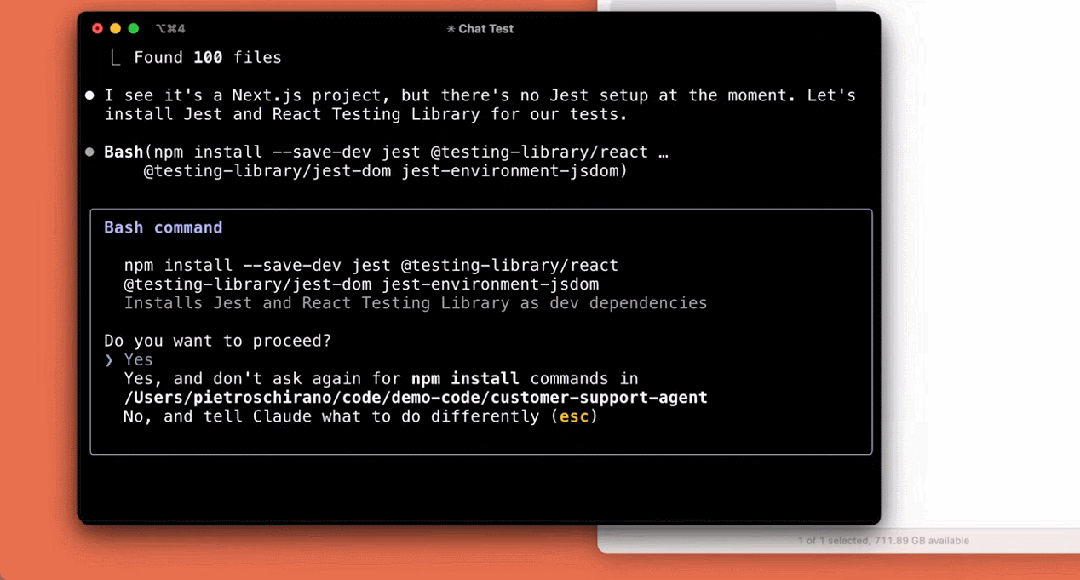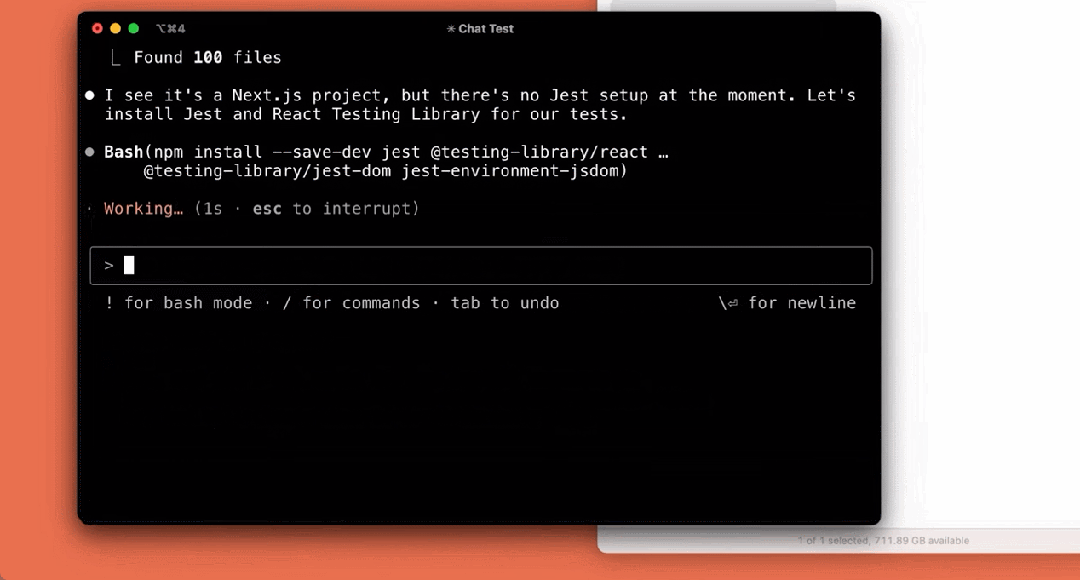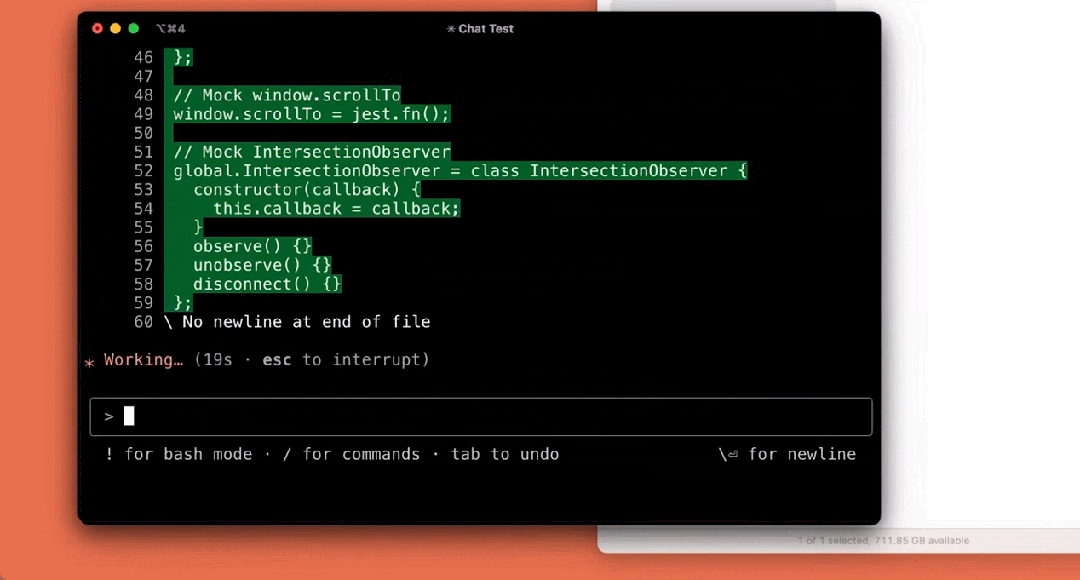
构建应用:
Claude Code 虽是一款早期产品,但对于 Anthropic 团队而言已不可或缺,尤其可用于测试驱动开发,可用于调试复杂问题,还可用于大规模重构。
在早期测试阶段,Claude Code 具备这样的能力,即能够一次性完成那些通常需要 45 分钟以上通过手动工作才能完成的任务。这样一来,就减少了开发所耗费的时间以及开销。
Anthropic 计划在接下来的几周内,依据自身的使用情况持续对 Claude Code 进行改进。具体包括提升工具调用的可靠性,增添对长时间运行命令的支持,改善应用内的渲染效果,以及拓展 Claude 对其自身功能的理解。
Claude Code 的目标在于更深入地知晓开发人员运用 Claude 进行编码的方式,以此为未来的模型改进提供依据。当加入此预览版后,用户便能够使用 Anthropic 用来构建和改进 Claude 的那些相同的强大工具。
负责任构建与未来展望
Anthropic 对 Claude 3.7 Sonnet 展开了广泛的测试工作,同时也进行了评估。并且 Anthropic 与外部专家展开了合作,其目的是确保 Claude 3.7 Sonnet 能够符合自身的安全性和可靠性标准。
Claude 3.7 Sonnet 对有害请求和良性请求做出了更细致的区分。并且,相较于前代,不必要的拒绝降低了 45%。

CoT 忠实度评估结果。
Anthropic 在 Claude 3.7 Sonnet 的模型卡中,详细地对自身的负责任扩展策略评估进行了细分,同时也对其他 AI 实验室和研究人员应用于他们工作的情况进行了细分。另外,模型卡中概览了计算机使用所带来的新风险,其中包括快速注入攻击。它还解释了 Anthropic 是如何评估这些漏洞以及如何训练 Claude 来抵御和缓解这些漏洞的。
此外,模型卡研究了推理模型的潜在安全优势。同时,模型卡也研究了理解模型如何做出决策,以及模型推理是否真正值得信赖和可靠。

系统卡地址:
Anthropic 认为此次发布的 Claude 3.7 Sonnet 和 Claude Code 具有重要意义,标志着 AI 系统向前迈出了一大步,开始朝着真正增强人类能力的方向发展。凭借其具备的深度推理能力、能够自主工作以及有效协作的能力,我们更加接近了 AI 丰富和扩展人类能力的那个未来。
Anthropic 展示了一个令人兴奋的发展图景。希望在 2025 年,Claude 能成为独立自主工作数小时的专家级智能体。到 2027 年,希望 Claude 能够解决人工团队花费数年才能解决的挑战性难题。

本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://www.mjgaz.cn/fenxiang/274496.html
