
评估结果显示,最为先进的 LMM 经人类反馈来纠正结果的比例未达 50%。
交互式过程能够提升大多数 LMM 解决难题的性能。而现有的 LMM 在解释和整合反馈这方面的表现是欠佳的。进行额外的迭代并不一定就能够得出正确的解决方案,高质量的反馈是非常重要的。
人类在解决问题时具备很强的适应性,能够依据反馈持续学习并加以完善。同样,先进的 LMM 也应当可以从反馈里进行学习,进而提升解决问题的能力。
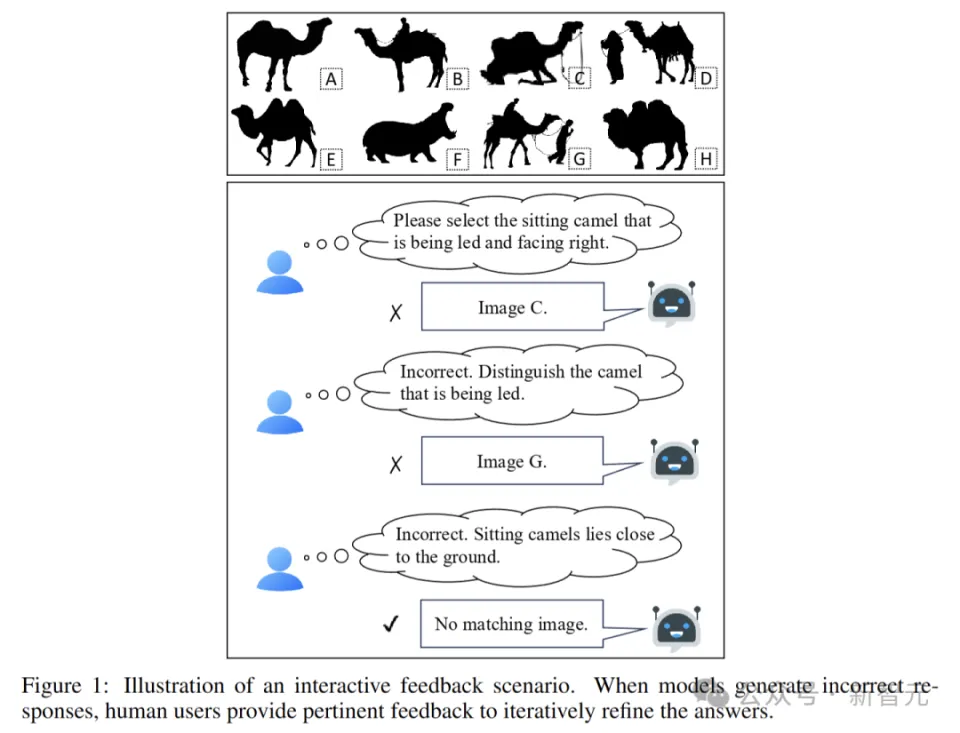
评估 LMM 交互智能的关键挑战是自动模型测试。因为不同模型对相同查询的响应不一样,所以需要人类在每一个对话轮次里提供定制化的反馈。
InterFeedback框架设计原理
研究人员提出了 InterFeedback,它是一个框架且基于交互式问题解决。借助 GPT-4o 等模型来模拟人类反馈,从而使 LMM 能在动态交互环境中进行测试与学习。
InterFeedback-Bench把带有反馈的交互式问题解决过程转化为一种数学模型,这种数学模型被称作部分可观测马尔可夫决策过程(POMDP)。
模型通过状态空间、观测值、动作空间、转移函数和奖励函数等要素,能够精确地描述其在交互过程中的行为和决策。
在实际应用里,要是给定了自然语言问题以及输入图像,模型会依据当前状态去获取观测值,接着生成自然语言回复。奖励函数是以精确匹配这种方式来判断任务是否正确的,并且能为模型给予反馈信号。
数据集构建
InterFeedback-Bench运用了两个具有挑战性的数据集,分别是 MathVerse 以及 MMMU-Pro。
MathVerse 是一个数据集,它属于视觉数学问题范畴。这个数据集中包含着各类问题,这些问题需要将图像与数学知识相结合才能得以解决。
MMMU-Pro 是综合性的多模态基准测试,它涵盖了多个领域的问题,这些问题属于专家级水平,包含科学、技术、工程和数学等领域。
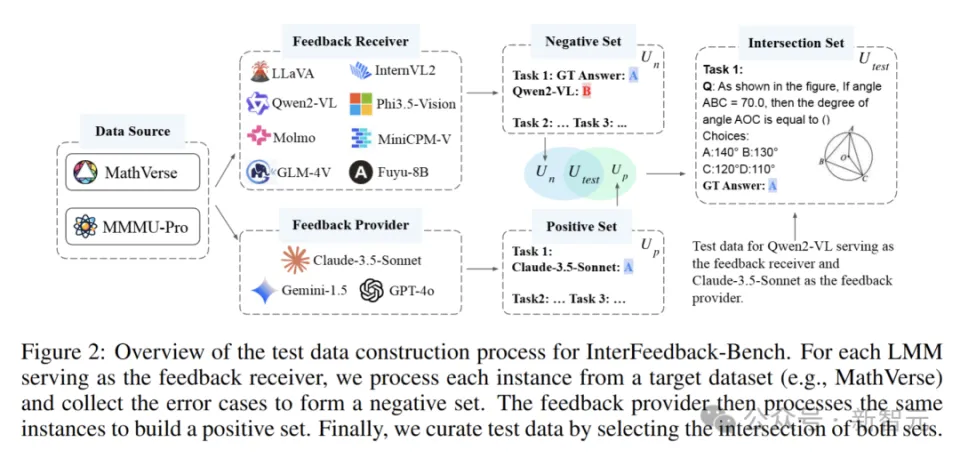
利用 LMM(比如 GPT-4o)进行巧妙的模拟人机交互,从而构建出有针对性的测试数据集。
具体来说,通过挑选出反馈提供模型 M_p 答对且反馈接收模型 M_r 答错的那部分内容,以此来保证反馈的相关性与可靠性。
InterFeedback框架
InterFeedback 框架存在两个角色,一个是反馈接收者 M_r,另一个是反馈提供者 M_p。
M_r 是将要接受基准测试的 LMM,例如 Qwen2-VL。M_p 是目前最为优秀的 LMM,像是 GPT-4o,它会在每个时间步代替人类来提供反馈。
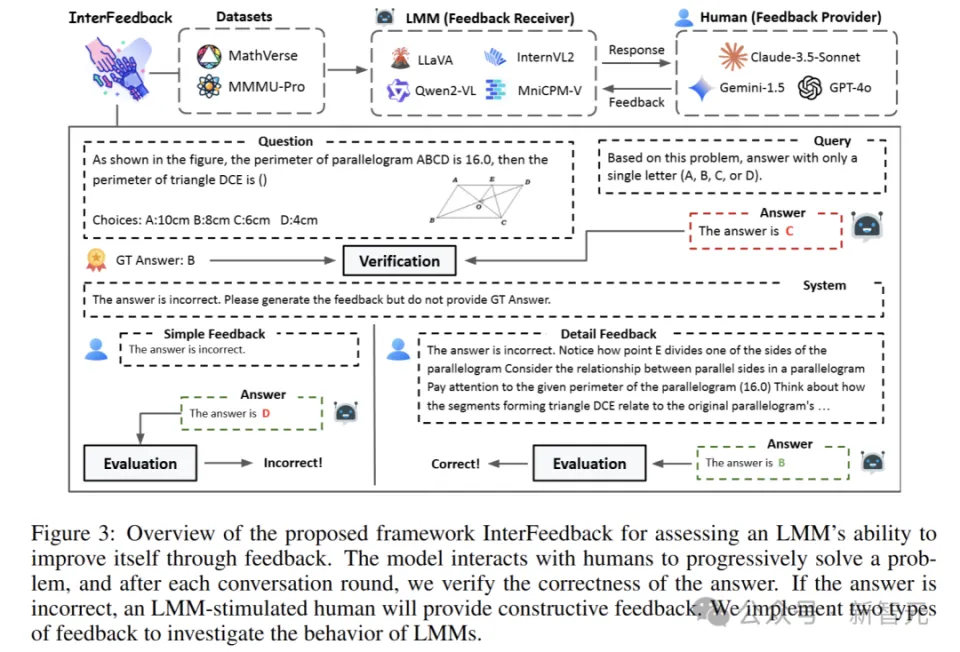
M_r模型生成输出之后,M_p依据映射策略给予反馈,模型按照反馈进行改进,接着继续循环,直至获得正确答案或者达到预先设定的迭代次数。
在这个过程里,M_r 依据当下的状态以及观测到的信息,把相应的动作生成出来。M_p 按照模型的回答,给出反馈信息,以此来协助模型对自己的回答进行改进。
团队基于 InterFeedback 框架构建了 InterFeedback-Bench 基准测试。此基准测试的目的是全面对 LMM 的交互式问题解决能力以及反馈学习能力进行评估。
人类评估基准测试
研究团队除了收集自动基准测试的数据外,还收集了用于人工评估闭源模型的 InterFeedback-Human 数据集。
自动基准测试有所不同,InterFeedback-Human 数据集在评估过程中更强调人类的参与与反馈。用户依据模型的回答,给出详细的反馈内容,涵盖对问题的剖析、正确的思考路径以及答案等方面。
这种方式能够让我们更深入地知晓模型在实际人机交互里的表现,也能知晓它们理解和处理人类反馈的能力。
实验结果与分析
研究人员设计了一系列实验,这些实验是在 MathVerse 和 MMMU-Pro 这两个具有代表性的数据集上进行的,并且对多个开源 LMM 进行了全面评估。
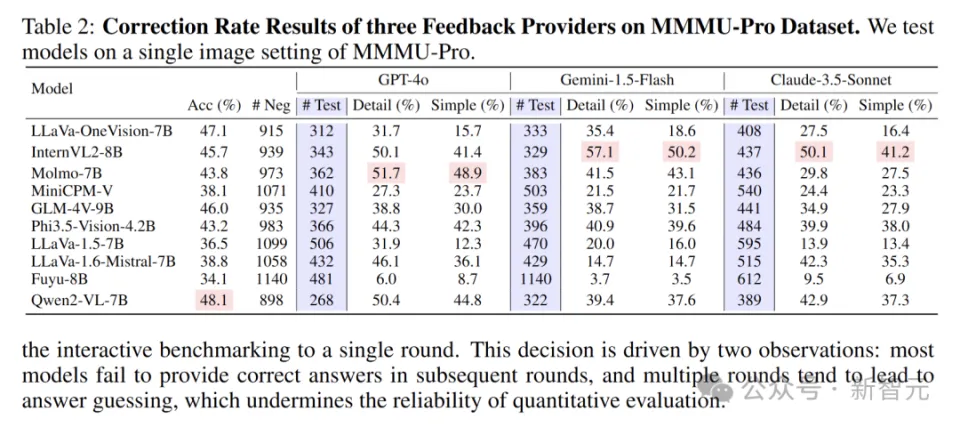
通过准确率和纠错率对结果进行评估,纠错率的定义是:在所有错误样本当中,被纠正答案的样本所占的百分比。其中,N 代表样本的总数,N_e 代表错误样本的数量,N_c 代表已经被纠正的样本数量。
准确率和纠错率可以用以下公式表示:
交互过程能提高性能
实验结果说明,交互式过程对大部分 LMM 的性能提升具有明显的促进性作用。
InterFeedback 框架具备让大多数模型从特定模型(如 GPT-4o 和 Claude-3.5-Sonnet 等)所提供的反馈里获得益处的能力。
即使是性能较为逊色的 Fuyu - 8B 模型,凭借 GPT - 4o 的反馈,也能够纠正 24.1%的错误样本。这显示出交互过程能够对大多数 LMM 解决问题的能力起到有效提升的作用。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://www.mjgaz.cn/fenxiang/274996.html
