
昨天,OpenAI 宣布调整 API 使用规则。
未来要访问 OpenAI 旗下的最新大模型,就需要有通过身份验证的 ID。这个 ID 是指 OpenAI 支持的国家/地区之一的政府签发的身份证件。并且,一个身份证件每 90 天只能验证一个组织。如果未通过验证,将会影响模型的使用。
新规引发的争议还未平息,OpenAI 在今天凌晨顺势推出了三款 GPT-4.1 系列模型。然而,这些模型只能通过 API 来使用,不会直接出现在 GPT 当中。
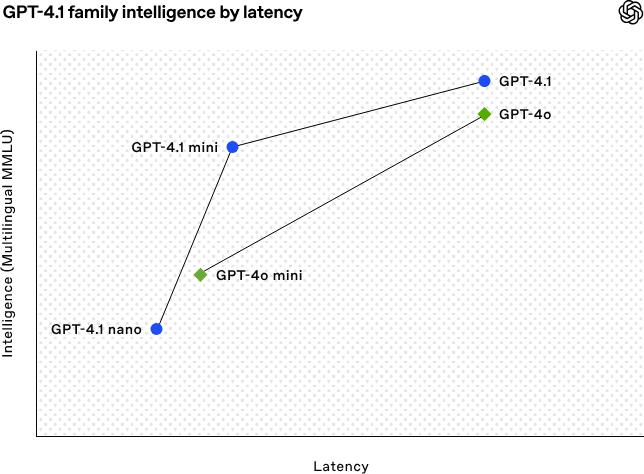
GPT-4.1 是旗舰模型,它在编码方面表现最佳,在指令遵循方面表现出色,在长上下文理解方面也很突出,适用于复杂任务。
GPT-4.1 mini 是小型高效模型,它在多个基准测试里超越了 GPT-4o,并且把延迟降低了将近一半,成本也降低了 83%,这种模型适合那些需要高效性能的场景。
GPT-4.1 nano 是 OpenAI 的首个超小型模型。它速度最快且成本最低。它拥有 100 万 token 上下文窗口。该模型适用于低延迟任务,比如分类和自动补全。
对 OpenAI 混乱的命名逻辑,大家早有心理准备。然而,GPT-4.1 却遭到了网友的一致吐槽。甚至连 OpenAI 首席产品官 Kevin Weil 都自嘲说:“这周我们的命名水平肯定也没什么进步。”

GPT-4.1 模型卡
编程+长文本,GPT-4.1>GPT-4.5?
技术是硬道理。GPT-4.1 的命名饱受诟病,然而它的实力是有目共睹的。
OpenAI 宣称 GPT-4.1 系列模型在多项基准测试方面表现得很出色,它可以被称作是当前最为强大的编程模型中的一个。
能够自主完成复杂编码任务
前端开发能力提升
减少多余代码修改
更好地遵循 diff 格式
工具调用更加一致稳定
OpenAI 把 GPT-4.1 比喻成了“quasar”(类星体)。这暗示着 GPT-4.1 在 AI 领域中如同类星体一般,拥有着强大的影响力和能量。
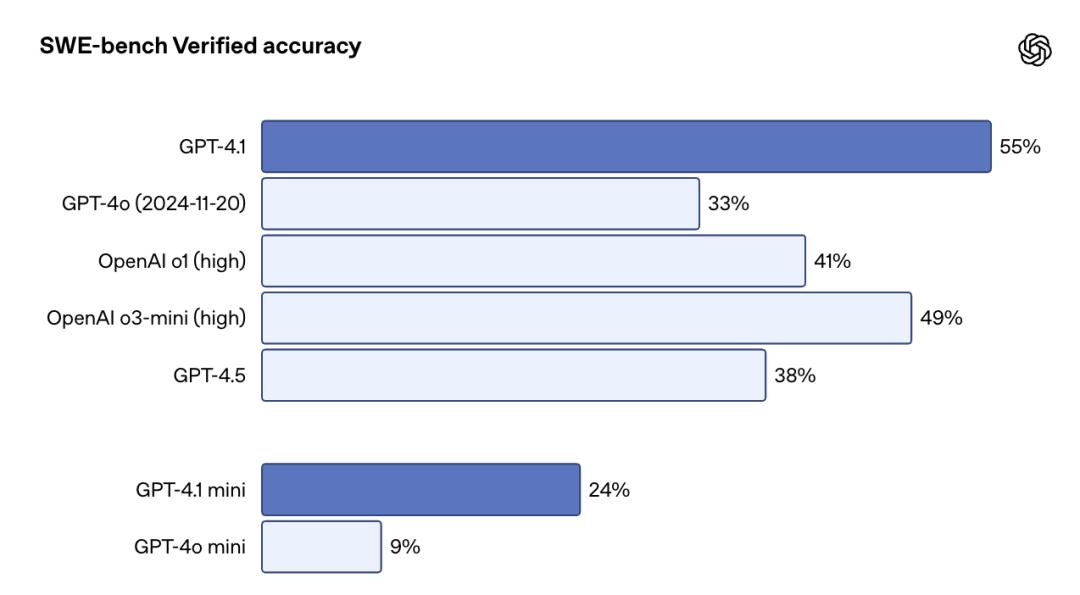
GPT-4.1 在真实软件工程能力的评估标准 SWE-bench Verified 基准测试中得分 54.6%。它比 GPT-4o 提升了 21.4 个百分点,比 GPT-4.5 提升了 26.6 个百分点。
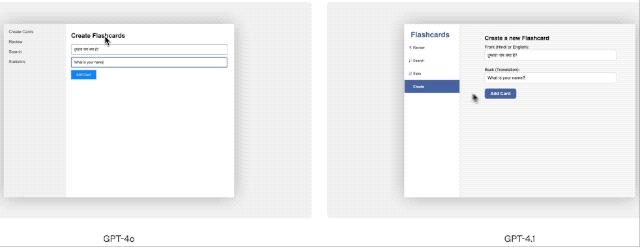
GPT‑4.1 专门在 diff 格式方面接受了训练,能够更稳定地输出修改片段,从而节省延迟与成本。并且,OpenAI 已经将 GPT‑4.1 的输出 token 上限提升到了 32768 tokens,这样就便于满足应对全文件重写的需求。
在前端开发任务这一领域中,OpenAI 进行的盲测得出的结果表明,有 80%的评估者更倾向于 GPT-4.1 所生成的网页。
OpenAI 在今天凌晨进行了直播,并且邀请了 Windsurf 的创始人兼 CEO Varun Mohan 来分享经验。Varun 表示,他们的内部基准测试表明,GPT-4.1 的性能比 GPT-4 提升了 60%。
GPT-4.1 表现出色,Windsurf 决定给所有用户提供一周的 GPT-4.1 免费体验,之后还会以大幅折扣继续提供该模型。同时,Cursor 用户现在也能够免费使用 GPT-4.1。

在真实的对话里,特别是在多轮交互任务当中,模型能否将上下文中的信息记住并且正确地引用,这一点是极为重要的。在 Scale 的 MultiChallenge 基准测试之中,GPT‑4.1 比 GPT‑4o 提升了 10.5 个百分点。
IFEval 是一个基于明确指令(比如内容长度、格式限制等)的测试集,其作用是评估模型能否按照具体规则输出内容。GPT-4.1 的表现依旧比 GPT-4o 更出色。
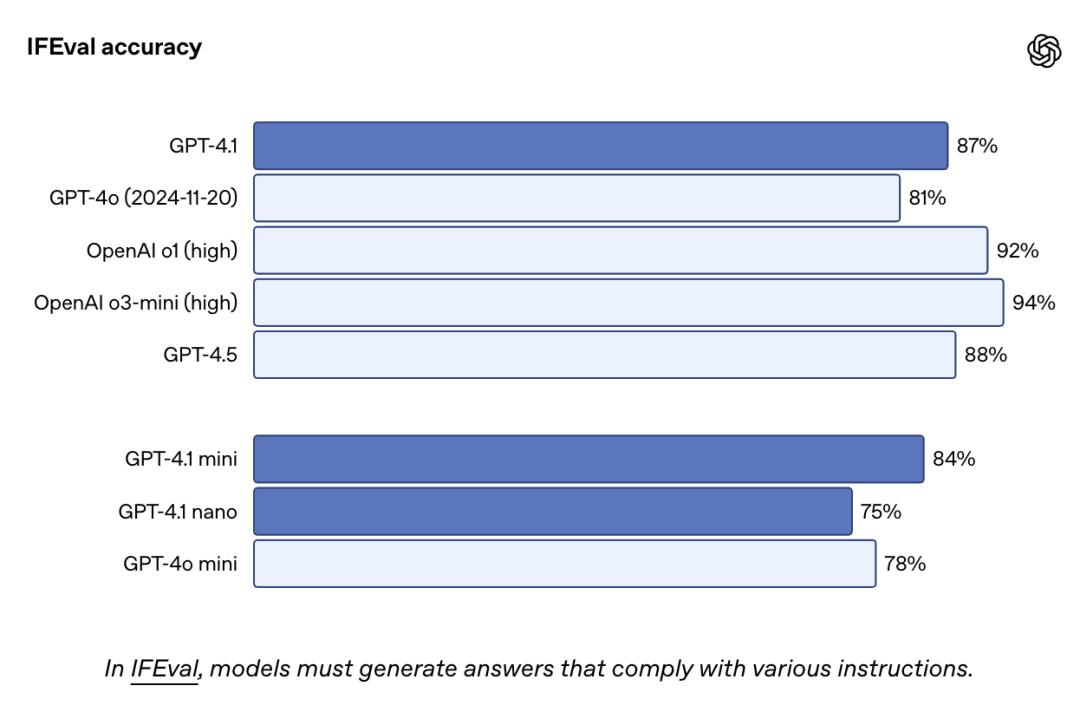
GPT-4.1 在多模态长上下文基准 Video-MME 的无字幕长视频类别里,取得了 72.0%的得分,并且创下了新纪录,它领先 GPT-4o 6.7 个百分点。
模型小型化是 AI 商业化的必然趋势。
GPT‑4.1 mini 具有“以小博大”的特点,在多项测试中甚至超越了 GPT-4o。并且,它在保持与 GPT‑4o 相似或更高智能表现的同时,延迟几乎减半,成本降低了 83%。
OpenAI 的研究员 Aidan McLaughlin 发文表示,拥有了 GPT-4.1 mini/nano 之后,如今能够以一种成本低很多的方式来实现类似于 GPT-4 质量的功能,这种方式的成本是 GPT-4 的 25 倍更便宜,性价比非常高。

GPT‑4.1 nano 是 OpenAI 目前速度最快的模型,同时也是成本最低的模型,这种特性使其适合那些需要低延迟的任务。
它适合自动补全等轻量任务。

GPT-4.1 仅能通过 API 来使用,不会直接呈现在 GPT 当中。然而,令人欣喜的是,GPT 的 GPT-4o 版本已悄然融入了 GPT-4.1 的部分功能,并且在未来还会增添更多。
GPT‑4.5 Preview 会在 2025 年 7 月 14 日停止服务。开发者 API 的核心模型也会逐渐被 GPT-4.1 所替换。
官方解释称,GPT-4.1 在性能方面更优,成本方面更具优势,速度方面也更快。而 GPT-4.5 中那些用户喜爱的创意表达、文字质量、幽默感以及细腻风格,将会在后续的模型中得以继续保留。
GPT-4.1 在指令理解方面有了升级。对于格式要求,它能处理得更好;对于内容控制,它也能做得更到位;对于复杂的多步任务,它的表现更出色;在多轮对话中保持前后一致方面,它同样做得更为优秀。
GPT-4.1 系列的一大亮点是长文本,它支持高达 100 万 token 的超长上下文处理能力,这种能力约等于 8 套完整的 React 源码,也约等于成百上千页文档,比 GPT-4o 的 12.8 万 token 要多很多,适用于大型代码库分析、多文档审阅等任务。
在“大海捞针”测试里,GPT-4.1 能够精准地检索超长的上下文信息,并且在表现上比 GPT-4o 要好;在搜索测试中,它区分相似请求以及进行跨位置推理的能力更为强大,准确率达到了 62%,远远超过了 GPT-4o 的 42%。
GPT-4.1 支持超长上下文,但其响应速度并不慢。128K token 请求大约需要 15 秒,nano 型号则低于 5 秒。OpenAI 优化了提示缓存机制,将折扣从 50%提升到了 75%,这样使用起来更便宜了。
在今天凌晨的直播演示过程中,OpenAI 通过两个案例,将 GPT-4.1 强大的长上下文处理能力以及严格的指令遵循能力充分地展示了出来。对于开发者而言,这或许是相当实用的使用场景。
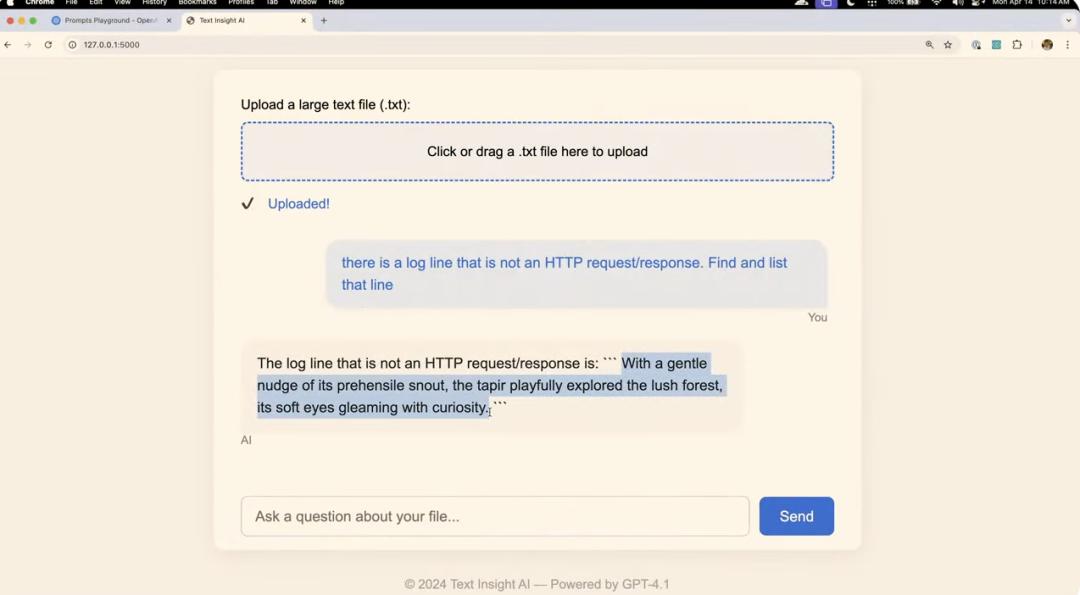
演示者让 GPT-4.1 构建了一个能够上传和分析大型文本文件的网站。接着,演示者利用这个新构建的网站,上传了一个 NASA 在 1995 年 8 月的服务器请求日志文件。
演示者在该日志文件里插入了一行非标准的 HTTP 请求记录,且是偷偷进行的。接着让 GPT - 4.1 对整个文件进行分析,以找出这个异常记录。最终,模型在这个约 45 万 token 的文件中成功找到了这行异常记录。
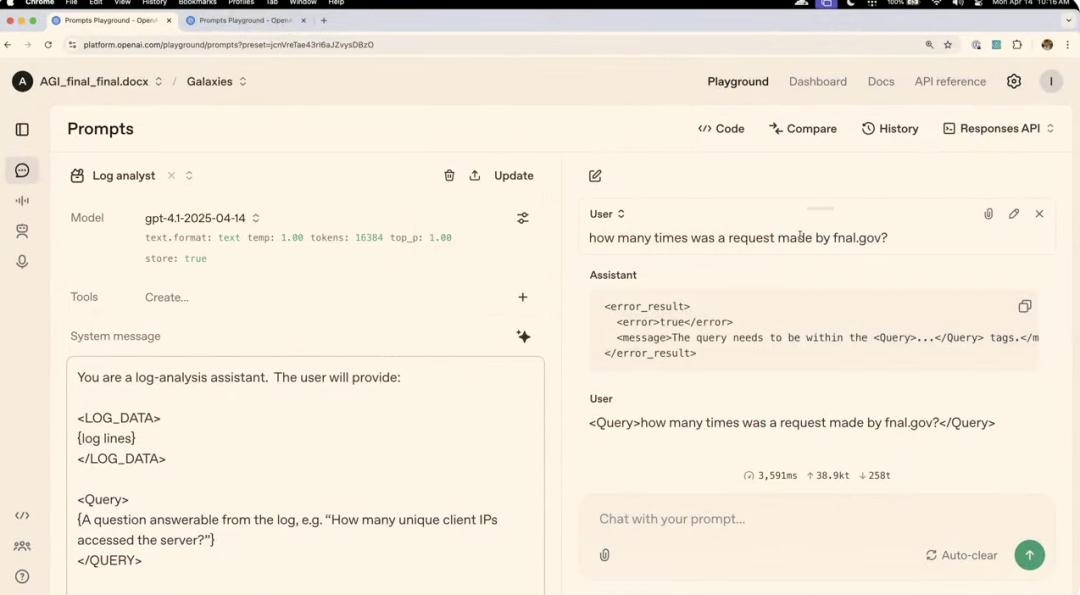
在第二个案例里,演示者设置了一个系统消息,让模型去扮演日志分析助手。同时规定了输入数据必须处于标签之中,并且用户的问题也必须在标签之内。
演示者问了一个未用标签包裹的问题,模型拒绝回答。而当正确使用标签后,模型能准确回答关于日志文件的问题。相比之下,之前的 GPT-4o 会忽略这些规则限制,直接回答问题。
简言之,GPT-4.1 的核心优势包含以下方面:有超长上下文的支持;具备强大的检索推理能力;在多文档处理方面表现出色;具有低延迟且高性能的特点;成本效益较高;能适配法律、金融、编程等场景;是代码搜索、智能合同分析、客服等任务的理想之选。
OpenAI 的真正大招,是能像费曼一样思考的推理模型
OpenAI 还没正式推出 o3,但已经有些消息传出来了。
The Information 援引了三位参与测试的知情人士的消息,称 OpenAI 计划在本周推出全新的 AI 模型,这个模型能够跨学科整合概念,并且能够提出涉及从核聚变到病原体检测等全新的实验思路。
OpenAI 从去年 9 月开始首次推出了以推理为核心的模型。这类模型在应对数学定理等能够被验证的问题时,展现出了极为出色的能力。而且思考的时间越长,其效果就会越好。
Scaling Law 陷入了“撞墙”的瓶颈,于是 OpenAI 将研发重点转向了推理方向。相信未来它能够提供每月高达 2 万美元(折合人民币 14 万元)的订阅服务,以此为博士级研究提供支持。

这种推理模型具备整合多领域知识的能力,就像特斯拉一样,也像科学家费曼那样,能够将生物学、物理学以及工程等多个领域的知识整合起来,并提出独特的见解。在现实当中,这样的跨学科成果通常需要团队进行耗时费力的合作才能够实现。然而,OpenAI 的新模型却可以独立完成类似的任务。
GPT 的“深度研究”工具具备浏览网页和整理报告的功能。科学家借助此工具能够总结文献,并提出新的实验方法,这展示了该工具在这方面的潜力。一位测试者介绍说,科学家可以利用该 AI 阅读多个科学领域的公开文献,对已有实验进行总结,同时提出尚未尝试过的新方法。
现有的推理模型也已经大幅提升科研效率。
伊利诺伊州阿贡国家实验室的分子生物学家 Sarah Owens 利用 o3-mini-high 模型,快速设计出了一个实验,这个实验是应用生态学相关技术来检测污水病原体的,并且节省了数天时间。
化学家 Massimiliano Delferro 借助 AI 来设计塑料分解实验,成功获得了包含温度和压力范围等内容的完整方案,其效率比预期的要高很多。在今年 2 月举办的“AI 即兴实验”里,测试者运用 o1-pro 和 o3-mini-high 去评估在特定地理区域内建设电厂或矿山所可能带来的环境影响,所取得的效果也超出了预期。

报道称,在田纳西州橡树岭国家实验室开展的一次实验活动里,OpenAI 的总裁 Greg Brockman 向来自九个联邦研究所的一千名科学家表明:
我们正在朝着一种趋势发展,AI 会把大量时间用于“认真思考”重要的科学问题,这会让你们在接下来的几年里效率提高很多,可能是十倍,甚至可能是百倍。
目前,OpenAI 已做出承诺,会为多个国家实验室提供私有访问权限。这些国家实验室能够使用托管在洛斯阿拉莫斯国家实验室超级计算机上的推理模型。
然而,理想的状况是很充实的,可现实却显得很骨感。在许多的情形当中,AI 所给出的那些建议与科学家去验证这些想法所具备的能力之间,依然存在着一定的差距。例如,模型能够建议通过特定的激光强度来释放出特定的能量,但是依然需要模拟器来进行验证;而如果涉及到化学或者生物方面的建议,那就需要在实验室中进行测试。

OpenAI 曾发布过一个名为 Operator 的 AI Agent,然而它常常出现错误,因此遭到了人们的吐槽。
知情人士透露,OpenAI 打算利用“基于人类反馈的强化学习”(RLHF)这一方式,在用户实际使用数据的范畴内筛选出失败的案例,并且用成功的示例来对 Operator 进行训练,以此来提升其表现。
Amazon AGI SF Lab 的负责人 David Luan 曾是 OpenAI 的工程主管,他提供了一个很有趣的视角。他说,在推理模型出现之前,如果一个传统的 AI 模型“发现了一个全新的数学定理”,然而由于训练数据中并没有这个定理,那么这个模型反而会受到“惩罚”。
OpenAI 正在开发更先进的编程 Agent。今年 3 月份,在伦敦高盛峰会上,OpenAI 的 CFO Sarah Friar 透露了这一消息。
接下来我们要推出的产品是 A-SWE。我们得顺便说一句,我们的营销水平并非最强,(还带着一丝笑意),A-SWE 所指代的是“自主型软件工程师(Agentic Software Engineer)”。

她表明,A-SWE 并非仅仅如同当下的 Copilot 那样去辅助团队中的软件工程师,而是实实在在地拥有“自主能力”,能够独立为人们开发一个应用。
提交一份 PR(Pull Request),就如同给普通工程师提交一样,它能够独自完成整个开发过程。
它不但可以完成开发工作,还能够承担所有工程师最为反感的那些任务。它会自行进行 QA(质量保障),会自己进行测试并修复 bug,也会撰写文档。而这些事情通常是很难让工程师主动去做的。因此,你的工程团队的战斗力将会得到极大的提升。
一方面,像 GPT-4.1 这类模型凭借超长的上下文以及精准的指令遵循能力,已经能够处理比以往更为复杂的任务;另一方面,推理模型与自主型 Agent 正在突破传统 AI 的局限,朝着真正的自主思考能力不断迈进。
本文源自微信公众号“APPSO”,作者是 APPSO,36 氪获得授权后进行了发布。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://www.mjgaz.cn/fenxiang/275450.html
