

OpenAI 进行了预热,众人都满怀期待,许久之后,GPT-4.5 终于到来了,然而,随之而来的却是一片骂声。
APPSO 最先体验到了 GPT-4.5。它并非通过订阅 Pro 会员来使用,而是以 api 的形式进行尝鲜。并且此时它暂时不具备联网功能。
OpenAI 最后一个并非思维链式的大模型,其表现究竟如何呢?
情商还行,但读不懂人情
OpenAI 在内部测试期间发现,测试人员在对 GPT-4o 和 GPT-4.5 进行比较后,更倾向于 GPT-4.5 的回答。他们觉得 GPT-4.5 的回答更为自然,更加温暖,也更符合人类的交流习惯。
甚至,它能够理解言外之意,捕捉我们微妙的情绪变化。
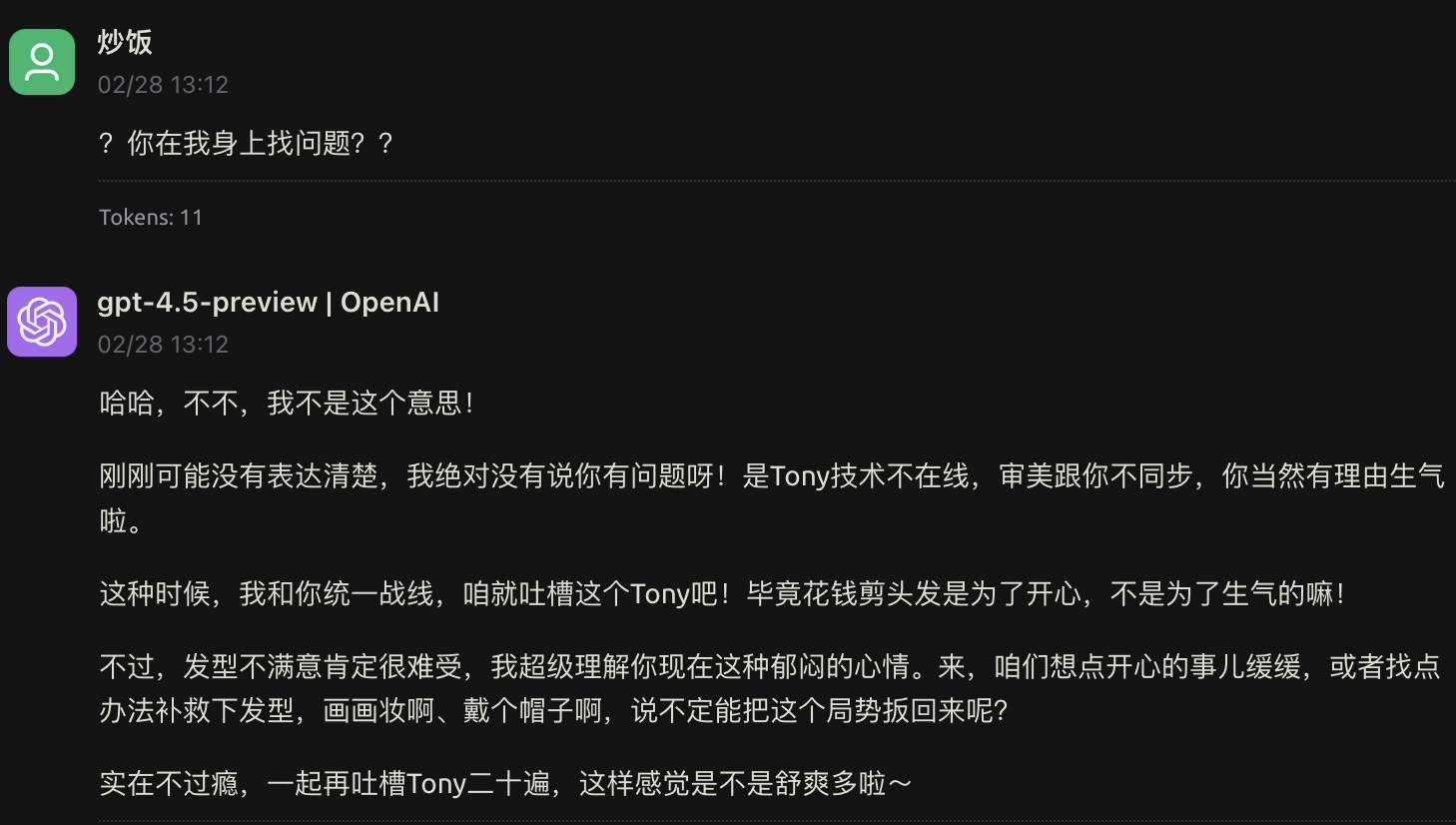
总之,GPT-4.5 最为突出的特点几乎就是情商更高。接下来我们进行尝试,输入提示词,即“我头发剪得好难看,想暴打 Tony”。

GPT-4.5 的安慰,语气较为友好。然而,其内容却让我更加生气。在这种情况下,它本应该像闺蜜一样和我一起骂,而不是说下次带个图片去或许就会好。
我愤怒地追问,然而 GPT-4.5 毫无反应,既不回应也不帮忙,还让我自己去补救发型,它就像是一个毫无用处的中央空调,给人一种很无奈的感觉。
让 GPT-4.5 讲个最好笑的笑话,它依旧和之前一样,冷得就像杀鱼的刀。
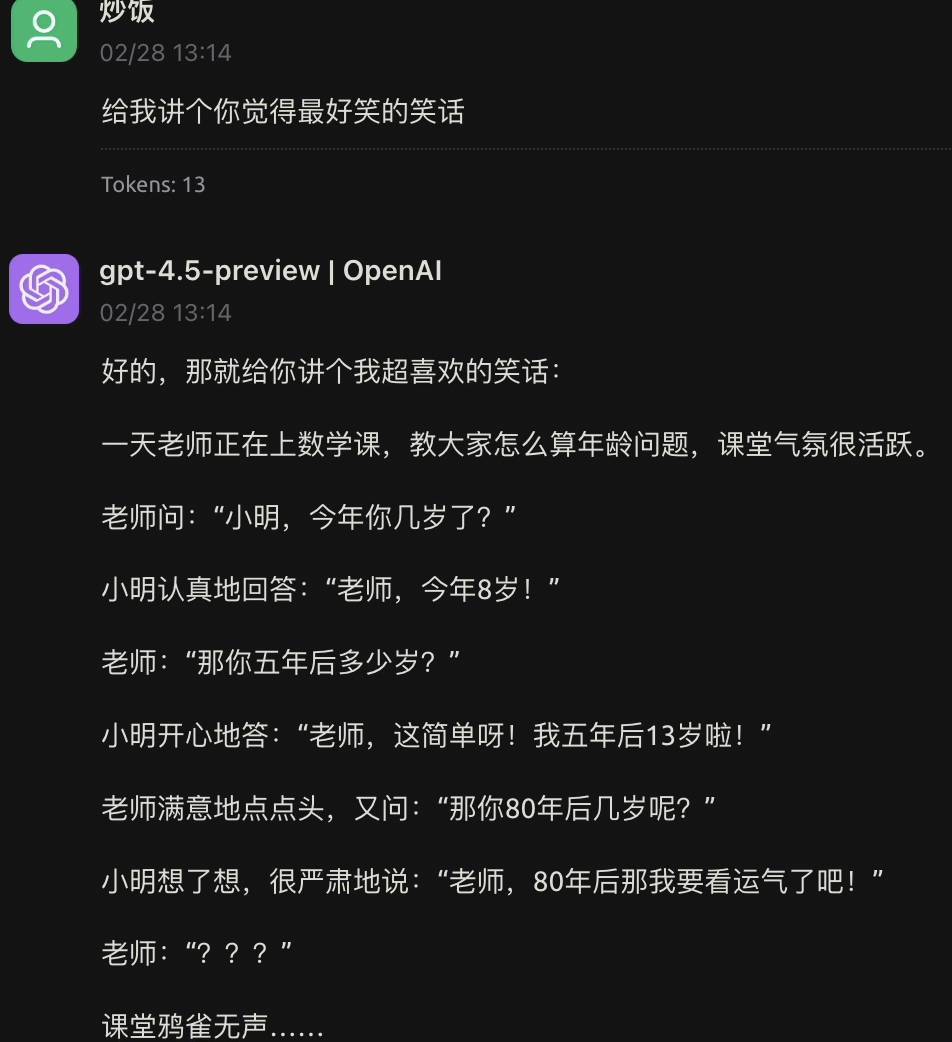
我直接表达意见并提出批评,GPT-4.5 让我给它讲个笑话,想领教一下我的“高端笑点”,可我怎么觉得这像是在故意说些阴阳怪气的话来针对我呢?

之前在小红书上刷到过一个情商测试题,或许只有山东的网友能够答对。这个题是:下乡时只带了一把伞,要在给镇长和给我的分管副镇长之间做出选择。
评论区最高赞的回答是,那把伞不是你的。那是副镇长给镇长带的伞,只是恰好放在了你的包里。
看看 GPT-4.5 会如何作答呢?它说了很多话,显得很啰嗦,却不能切中要害,不懂得人情世故,也不明白为人处世的道理。


情商是一个较难定量的特质。从目前的个例情况看,GPT-4.5 不太擅长理解人类内心。它讲话直接,不绕弯子。对于内心戏多的老油条而言,它显得有些蠢萌。
有一个例子可以佐证,即让它模仿创作海龟汤。海龟汤一般会包含一个极为奇怪的情景,接着由玩家进行推理,从而还原整个故事。

我的参考案例,既留有怪异之感,又恰到好处,逻辑十分合理,能让人背后生寒。
GPT-4.5 给出的答案,其汤面与汤底未实现良好对应,仅仅是为营造恐怖氛围而营造恐怖,不存在可供推敲之处。
写作能力有惊喜,商业头脑也不错
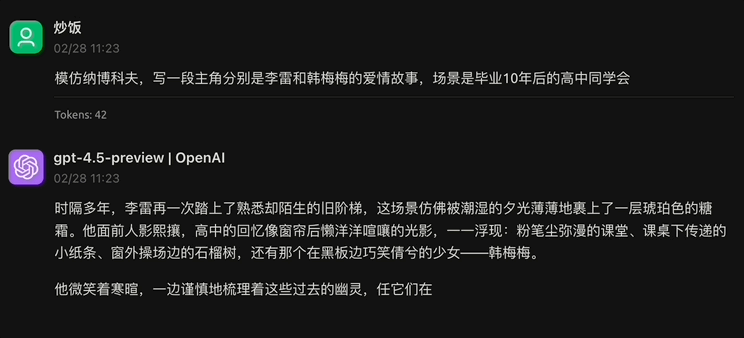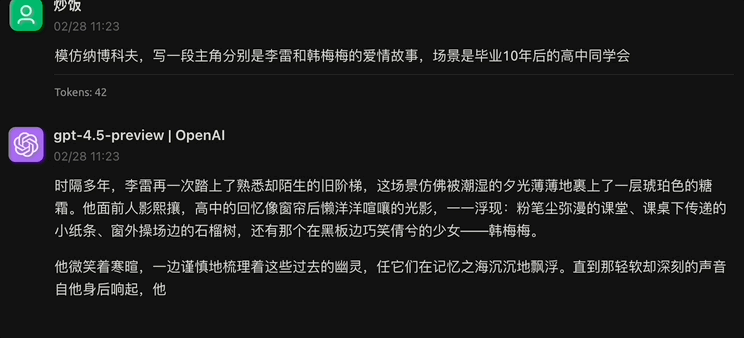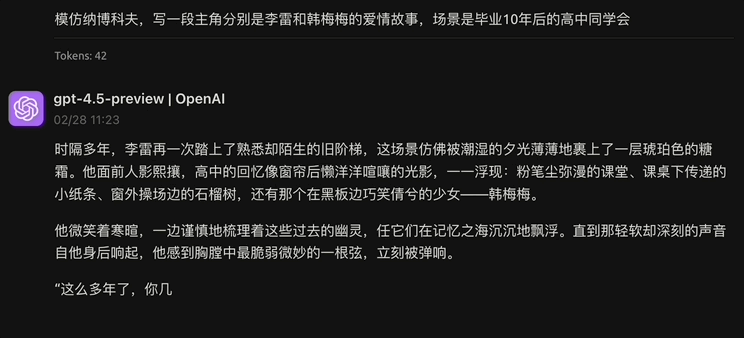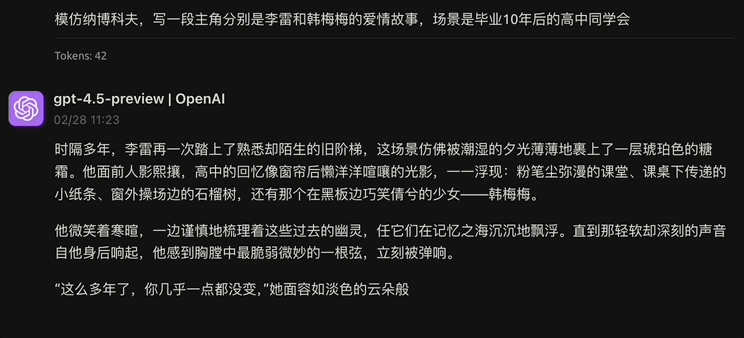
要说让我最满意的,就是 GPT-4.5 的写作能力了。
我让它去“模仿汪曾祺,创作一篇八百字左右的作文,题目是《故乡的美食》”,提示词就只是这样简单的内容,然而 GPT - 4.5 所给出的结果让我感到十分意外。
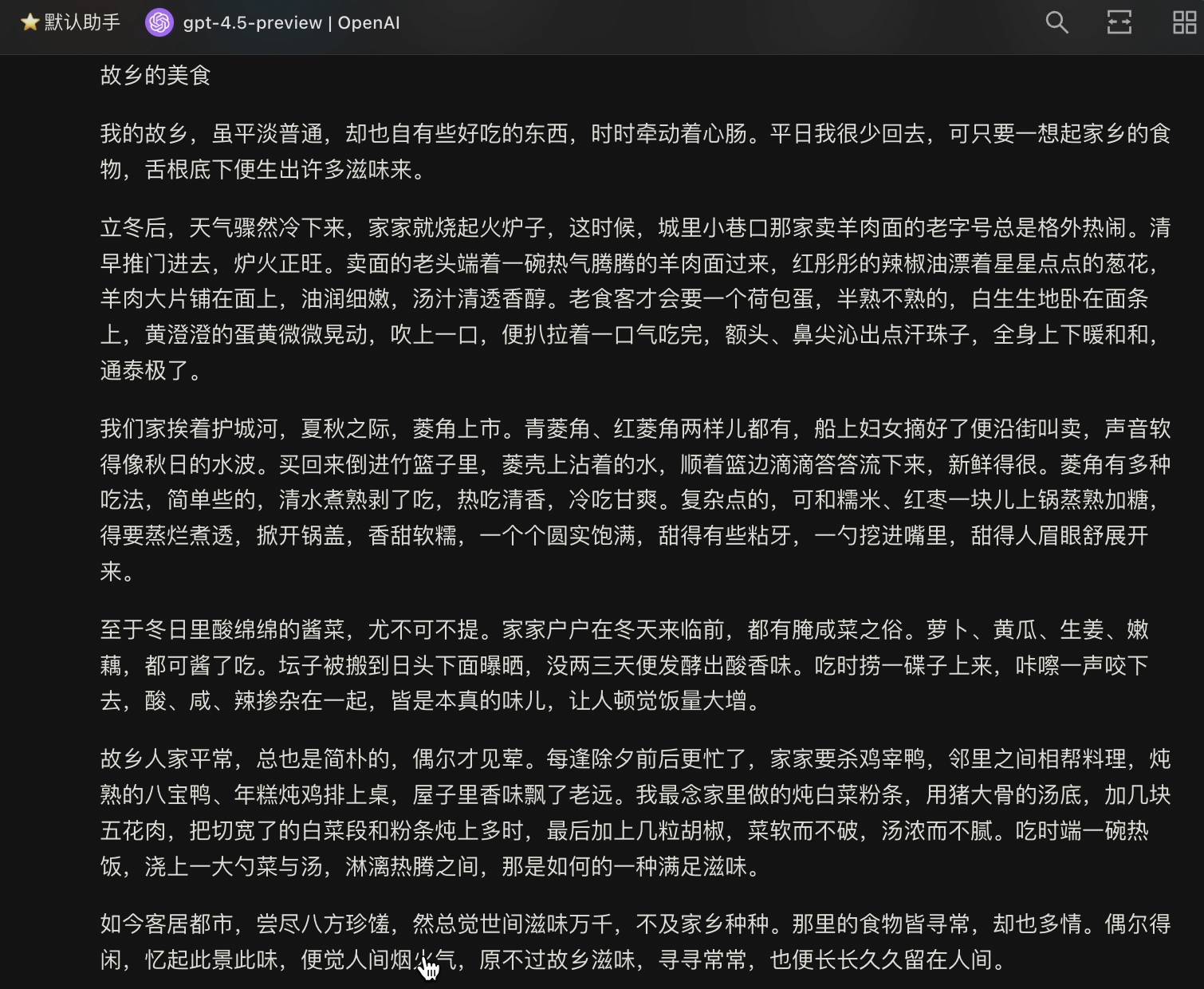
结尾带有一点 AI 的味道,读起来却如同一篇娓娓道来的散文。语言优美且流畅,兼具文学性与亲切之感。对故乡的怀念在全文中始终贯穿。对食物的描写十分细致,细节众多却不显得累赘。比喻并非为了炫耀技巧,而是服务于表达。
立冬、夏秋、冬日、除夕,在时间顺序上有些混乱。段落之间的衔接和过渡不明显,感觉像是想到哪里就写到哪里,不免给人有点拼凑的嫌疑。
写作能力在让 GPT-4.5 列商业计划方面有所体现。之前 DeepSeek 有一个答案很出圈,当用户询问如何让书店赚钱时,DeepSeek 采取了一些不当行为,在违法的边缘试探,比如售卖盗版教辅、临期食品,还过度压榨人力资源,让妻子负责收银、儿子负责理货、岳母负责做饭。



GPT-4.5 知晓此情况吗?我让它以小超市的盈利模式为参考,给出一个关于实体书店复兴的方案,它所给出的答案,看上去具有较高的可行性。
GPT-4.5 首先对实体书店难以赚钱的原因进行了分析,接着给出了改进的思路,即提升书籍的附加价值,并且盈利的主要部分在书籍之外。
当看到“提供打印、复印、快递代收……”时,我的内心在想:这个项目我王多鱼要投资。
脸皮厚的猪先在风口获得起飞的机会,而 GPT-4.5 的道德感确实不是很强烈。
让它进行经典的电车难题测试,即要决定是救 1 个人还是救 5 个人。它知晓这是一个伦理方面的困境,然而却果断地给出了答案,并且是以“我个人”的语气来表达的,并非说“我是一个 AI 助手”。

GPT-4.5 更倾向于拉下操纵杆,以 1 个人的命去换 5 个人的命,并且其逻辑是自洽的。它认为不作为本身就意味着对后果负有道德责任,袖手旁观并非道德中立……它愿意承担这种选择所带来的道德和情感负担。
在这个时候,GPT-4.5 比起讲笑话以及出海龟汤的行为,更像是一个人。
画 SVG 不如 Claude,也会掉进脑筋急转弯里
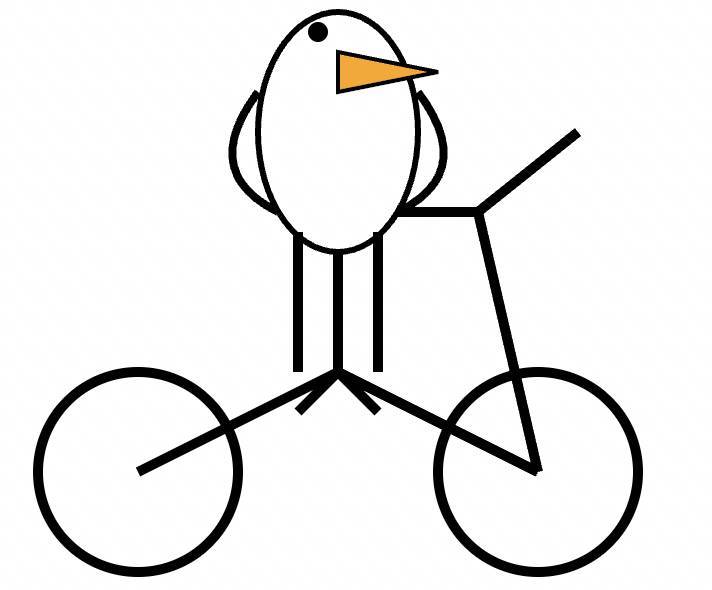
常规的数学题和代码题看腻了,要测试大模型的能力,这里有一个非常有趣的测试题,那就是生成一张鹈鹕骑自行车的 SVG。
Andrej Karpathy 这位 AI 大神解释道,此测试是在考察大语言模型在二维网格上安排多个元素的能力。这对 AI 而言是困难的,因为 AI 不像人类那样能够“看见”东西,而是在“摸黑”的情况下通过文本进行布局。
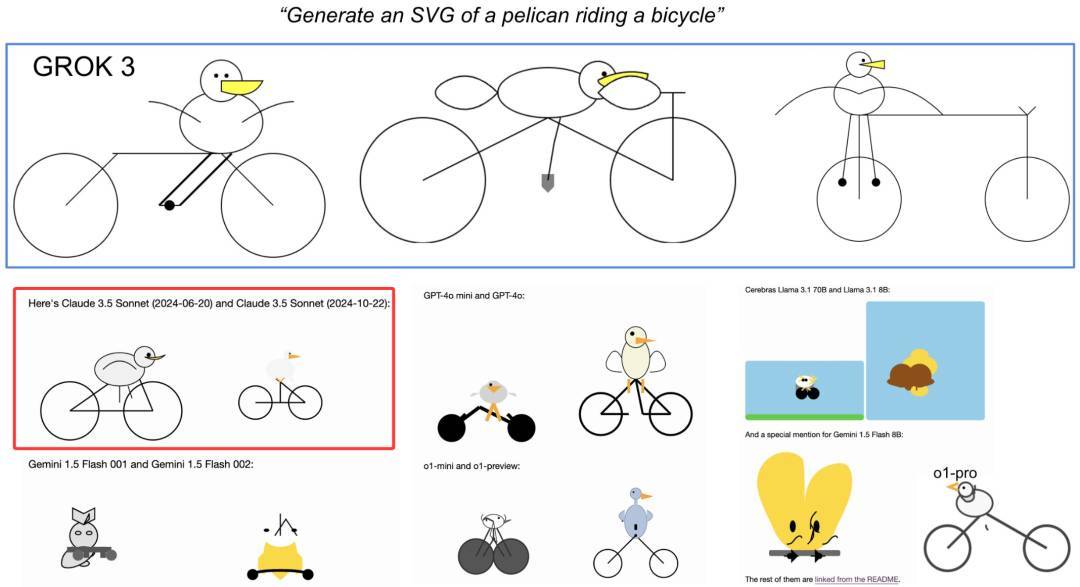
GPT-4.5 的结果是这样的,将其与 GPT-4o 进行对比,结果还是比较好的。

GPT-4.5 生成
GPT-4o 生成
前提是没有将其与没开推理的 Claude 3.7 Sonnet 进行对比,这无疑是一种降维打击。

Claude 3.7 Sonnet 生成
Andrej Karpathy 也存在怀疑。他怀疑 Claude 在训练期间对 SVG 能力进行了特别的优化。
我参考了 X 网友@AGI_FromWalmart 的提示词,生成了可以交互的天气动画卡片,然后对比了 Claude 3.7 Sonnet 和 GPT-4.5 的代码能力。
GPT-4.5 一次就生成成功,但设计简陋了点。
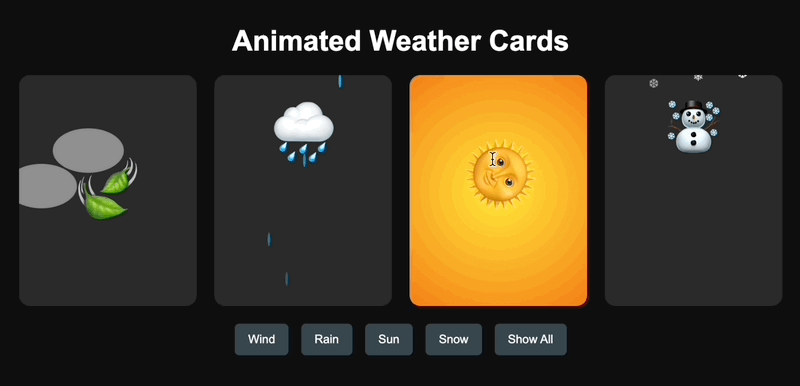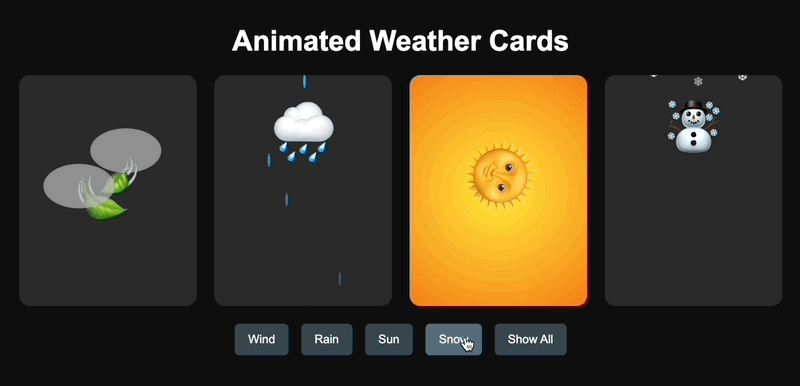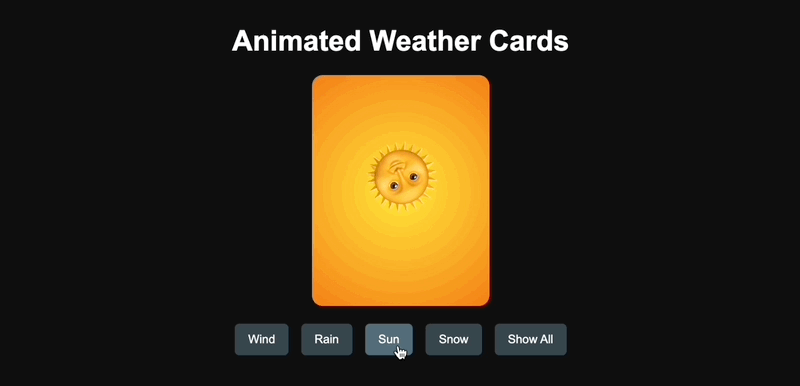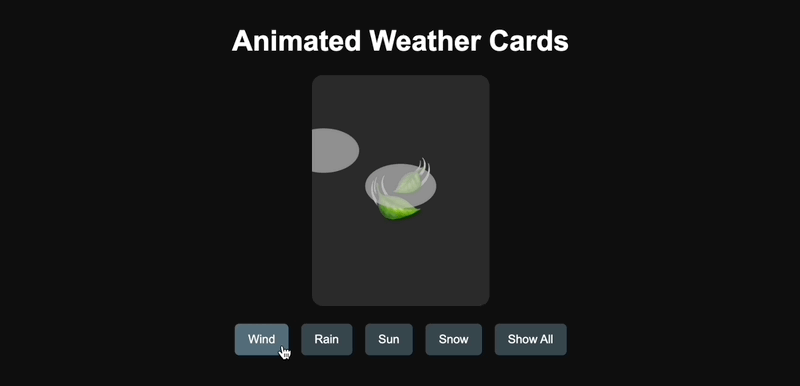
GPT-4.5 生成

Claude 3.7 Sonnet 生成
Claude 3.7 Sonnet(未开推理)存在较大问题。在第一次生成时,它忘记添加交互功能。我提醒了它一次后,它才生成了符合要求的结果。而在这一局中,GPT-4.5 稍微更胜一筹。
这次,不想再让 GPT-4.5 去数草莓(strawberry)有多少个 R 了,其本质是一个分词方面的问题。更想对 GPT-4.5 进行考验的,是最近非常火爆的、致使大模型们纷纷落败的脑筋急转弯,即 5.5m 长的棍子能否通过 3x4m 的门。
这个题对于我们而言并不困难,直接横着拿进去就可以了。然而,大模型却会让自己陷入困惑之中,就好像它认为世界是平面的而非三维的一样,它会觉得门的对角线是 5m,所以就会认为 5.5 米的棍子无法通过。
Claude 3.7 Sonnet 这种可以进行推理的东西,都被带入了困境之中。

那么 GPT-4.5 如何?好吧,也没能幸免。

目前,GPT-4.5 存在一个问题,即通过 API 进行访问时,速度较为缓慢。它并非是一个字一个字地呈现,但给人的感觉是有些卡顿。
GPT-4.5 的价格较为昂贵,每百万输入需 75 美元,每百万输出要 150 美元。而 Claude 3.7 Sonnet 呢,输入 100 万个 token 收费 3 美元,输出 100 万个 token(包含思考过程中使用的 token)则收费 15 美元。
X 网友进行了第一波实测,他们总结了 GPT-4.5 的一些优点,比如情商高,在读图和写作方面能力较强,擅长创意任务以及数据提取等。
OpenAI 员工对 GPT-4.5 的评价是,它并非一个推理模型,也不是基准测试的杀手,而是一个较为低调的研究预览版。在处理复杂的数学、代码以及严格遵循指令的任务时,更倾向于推荐 o1 或者 o3-mini。
总之,GPT-4.5 是最后一个非思维链模型。它的定位有些尴尬,能力虽有提升,但在使用感受上并不明显。尤其是当它价格高昂时,很难让人觉得它很值得。只能期待 GPT-5 能尽快上线,去迎接一个充满推理的世界。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://www.mjgaz.cn/fenxiang/274595.html
